The live demo repo for this series is 67ailab/harness-engineering, and this post stays anchored to the code that exists there today. I did not add a new repo capability for this article. The point of this installment is to dissect the current harness as it actually stands: what lives in src/harness_engineering/, how the pieces fit together, and which parts are carrying the reliability burden.
That matters because “agent” is now a dangerously overloaded word. Many teams still mean either a model that can call functions or a prompt loop with some memory and tool wrappers. Those are ingredients, not a runtime anatomy.
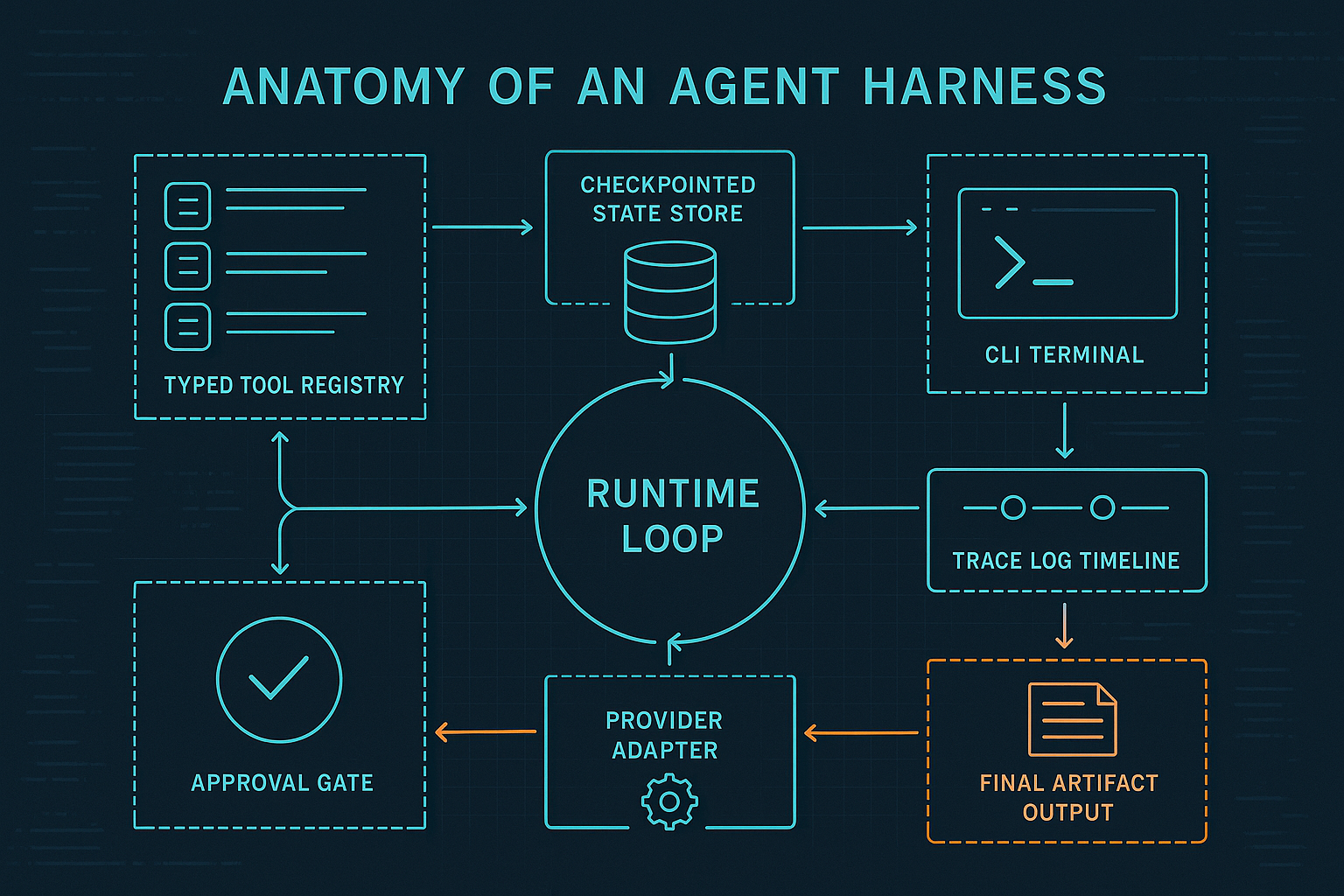
If you want a system that can pause before risky actions, survive interruptions, keep a trace, and explain itself after something goes wrong, you need a harness with clearly separated responsibilities. In the demo repo, those responsibilities are visible in code rather than hidden in framework abstraction.
The files that matter most for this post are:
src/harness_engineering/cli.pysrc/harness_engineering/runner.pysrc/harness_engineering/tools.pysrc/harness_engineering/store.pysrc/harness_engineering/models.pysrc/harness_engineering/provider.pysrc/harness_engineering/reviewer.pysrc/harness_engineering/tracing.py
Those files are small enough to read directly, which makes this repo a useful teaching specimen. It is not pretending to be a production platform. It is showing the bones.
The shortest useful definition of a harness
A harness is the runtime system around the model. In this repo, that runtime is not one giant “agent class.” It is a set of boundaries:
- the CLI starts and controls runs
- the runner owns workflow progression
- the tool registry defines available actions
- the store persists run state and trace artifacts
- the models define the durable data shape
- the provider/reviewer layer lets model-backed planning and review plug in without taking over the architecture
- the tracing helper records what happened as first-class events
That separation is the anatomy. It is also why this code is more instructive than a notebook demo: you can point at each responsibility and ask whether it has the right home.
Start with the command surface, because operations begin there
The entry point in src/harness_engineering/cli.py tells you a lot about the system before you even inspect the workflow logic. build_parser() defines the current subcommands:
startinspectapproveresumelistinteractivedoctor
That command set already implies a different operational model than “send prompt, get answer.”
A normal prompt-centric demo usually has one entrypoint: run the thing. This repo has separate commands for inspection, approval, and resumption because a run is treated as a long-lived object rather than a disposable response.
A few functions in cli.py are worth reading directly:
cmd_start()loads source documents, creates a run viaHarnessRunner.create_run(), then advances it withrun_until_pause_or_complete().cmd_inspect()loads a stored run and prints the serialized state JSON.cmd_approve()flips approval state throughHarnessRunner.approve().cmd_resume()re-enters the workflow after a pause.cmd_interactive()exposes the approval boundary to a human in one session.cmd_doctor()checks provider/model connectivity.
This is the first design lesson: the CLI is part of the harness contract. If a system claims to support approvals and resumability, there should be an explicit operational surface for both.
RunState is the real center of gravity
If you want to know what a harness truly believes about the world, look at its persisted state model.
In src/harness_engineering/models.py, the key dataclass is RunState:
run_idtopicstatuscreated_atupdated_atcurrent_steprequires_approvalapprovedpending_actionplansource_documentsartifactstracestep_results
That is the actual anatomy in data form. If something matters to the control flow, it should usually become explicit state.
A few aspects are especially important:
1. Approval is state, not chat etiquette
The pair requires_approval and pending_action, plus the approved boolean, turns human review into something the runtime can reason about. It is no longer an implied social convention.
That sounds almost trivial until you compare it with the usual pattern in thin agent wrappers:
- model suggests a risky action
- app displays a message like “Should I proceed?”
- a human responds somewhere in chat
- the system tries to reconstruct intent from message history
That is fragile. RunState makes the opposite choice.
2. Step results are distinct from trace events
The repo keeps both step_results and trace:
step_resultsanswer: what were the outcomes of concrete tool executions?traceanswers: what notable events happened over the life of the run?
3. Artifacts are part of the state contract
The artifacts dictionary stores intermediate and final outputs like matches, facts, draft markdown, review output, planner identity, and the finalized report path. That makes the harness introspectable after the fact.
If you inspect a stored run, you can see not just that it failed or paused, but what it had already produced.
The runner is the workflow brain, not the model
The heart of the repo is HarnessRunner in src/harness_engineering/runner.py.
This class owns the workflow semantics through:
create_run()_execute()run_until_pause_or_complete()approve()resume()
That method set is worth paying attention to because it encodes a strong architectural preference: the model can contribute to planning and drafting, but it does not own control flow.
create_run() establishes a run as durable work
create_run() does three important things:
- creates a new
RunState - derives a plan through
create_plan_from_env() - persists the run immediately and records a
run_createdtrace
This is a small design choice with big downstream effects. The run exists before useful work happens, so the system can be inspected even if it fails early.
_execute() is the control wrapper around tools
_execute() is where the harness adds operational behavior to plain function calls:
- look up the tool in the registry
- emit
tool_start - call the tool through retry logic
- append a structured
StepResult - emit either
tool_okortool_error - save state after execution
Model APIs can tell you that a tool call was requested. They do not automatically give you persistence semantics, retry policy, or artifact storage. _execute() is where the application becomes responsible.
run_until_pause_or_complete() is the state machine in plain sight
This method is the cleanest anatomy diagram in the whole repo. The workflow currently moves through:
search_mockextract_factsdraft_reportfinalize_reportdone
What matters is how the transitions are handled. At the draft_report stage, the runner stores draft_markdown, then calls review_from_env() and records a draft_reviewed event. If review passes, the runner does not immediately write the final artifact. Instead it sets:
current_step = "finalize_report"requires_approval = Truepending_action = "finalize_report"status = "waiting_approval"
Then it stops.
The write boundary is explicit, durable, and inspectable. When approval is later granted, approve() updates the state and resume() re-enters run_until_pause_or_complete().
The tool registry is where action contracts become legible
In src/harness_engineering/tools.py, the central abstractions are:
ToolToolRegistrydefault_registry()
The Tool dataclass includes:
namedescriptioninput_schemariskyhandler
A good harness should make tool availability and risk boundaries inspectable without needing to parse prompt text. Here, default_registry() registers:
search_mockextract_factsdraft_reportfinalize_reportflaky_echo
finalize_report is marked risky=True. Everything else is non-risky. That matters because it is the start of policy. Not a full policy engine, but the right shape.
The individual tool handlers are intentionally simple:
search_mock()scores local documents lexically against topic words.extract_facts()slices early sentences from matched documents into short fact strings.draft_report()callsbuild_report_markdown()with or without a configured model client.finalize_report()writes markdown to disk.flaky_echo()exists to test retry behavior.
Two practical observations follow.
First, boring tools are a feature in a teaching repo. This repo keeps the tool layer simple enough that the harness is still the main character.
Second, tools are application functions first, model affordances second. Even if future posts add an MCP-facing adapter or provider-neutral tool interface, these handlers will still need application-side semantics around retries, writes, persistence, and policy.
Storage is what turns a run into durable work
src/harness_engineering/store.py is short, but it has outsized importance.
RunStore provides:
run_dir(run_id)state_path(run_id)trace_path(run_id)save(state)load(run_id)list_runs()latest_run_id()
The implementation writes state.json and trace.json under .runs/<run_id>/.
That directory layout is humble, but it is exactly why the demo is inspectable. You can run the CLI, pause before approval, and open the saved artifacts directly.
Without a store like this, all of the following become much harder:
- resuming after interruption
- auditing prior actions
- exposing pending approval clearly
- comparing multiple runs
- writing tests around run lifecycle behavior
You can also see how little code it takes to get meaningful checkpointing. You do not need a giant orchestration platform to start behaving like a real system.
Tracing is separate on purpose
src/harness_engineering/tracing.py contains one small helper: add_trace().
At first glance, that file looks almost too small to mention. But the design choice behind it is good: trace creation is centralized, timestamped, and distinct from general artifact updates.
The events currently emitted include:
run_createdtool_starttool_oktool_errordraft_reviewedapproval_requiredapproval_grantedrun_resumedrun_completed
That event vocabulary is already enough to reconstruct a causal story about a run.
And the repo gives a useful real-world example of why that matters.
A verified limitation from this run: model-backed review is still brittle
Before writing this article, I verified the demo with:
PYTHONPATH=src python3 -m harness_engineering.cli doctorPYTHONPATH=src python3 -m harness_engineering.cli start --topic 'Agent harness anatomy' --source-file sample_data/sources.json
The doctor command succeeded against the repo-local OpenAI-compatible endpoint, with provider: openai_compatible, model_name: gemma4, and a successful MODEL_OK response.
But the live run did not reach approval. It failed in the review stage.
The stored run under .runs/e6c5f518-57d9-4f56-9c38-1f5ae029fa74/ showed why: review_from_env() in src/harness_engineering/reviewer.py expects raw JSON from the reviewer model, but the configured local model returned fenced JSON markdown. The runner then recorded:
status: "failed"current_step: "draft_report"- a
draft_reviewedtrace event withpassed: false - findings that included
Reviewer returned non-JSON output
That is not a reason to discard the harness. It is a good example of why the harness exists. The failure is visible, persisted, and explainable.
A thin “agent framework” demo might just shrug and tell you the agent failed. Here, you can inspect the exact review artifact and see the mismatch between expected and returned structure.
The provider boundary is intentionally narrow
src/harness_engineering/provider.py handles model configuration and OpenAI-compatible interaction through:
ModelConfigload_dotenv()load_model_config()OpenAICompatibleClientbuild_report_markdown()create_client_from_env()doctor_check()
This file demonstrates one of the healthier patterns in the repo: provider code is boxed in.
The provider layer knows how to:
- load environment-based configuration
- talk to
/models - send a chat completion request
- build a report draft from supplied facts
- validate connectivity through
doctor_check()
It does not own workflow transitions, trace persistence, approval logic, or artifact policy.
That is the right relationship.
A lot of projects accidentally let the provider abstraction swell until it starts dictating application semantics. This repo keeps the provider as an adapter, which makes the rest of the runtime easier to reason about.
The reviewer module is a quiet preview of future scaling problems
src/harness_engineering/reviewer.py contains:
build_plan()review_markdown()create_plan_from_env()review_from_env()
The repo already separates:
- planning from execution
- review from drafting
- provider-backed behavior from mock behavior
That separation is useful, but it also creates contract pressure. As soon as one component returns output that the next component expects in a stricter format, reliability starts depending on how carefully you define interface boundaries.
The fenced-JSON review failure is the obvious example. In later, larger systems, this is exactly where teams end up needing:
- stronger schemas
- output validation
- tolerant parsers
- typed envelopes for agent-to-agent handoff
- retry policies specific to structured-output failures
What the demo proves
This repo is still compact, but it proves several important design points cleanly.
1. A harness should have named parts, not one mystical loop
The split across CLI, runner, tools, store, models, tracing, provider, and reviewer makes the design inspectable. That is already better than many agent demos, where everything is buried inside framework callbacks.
2. The state model should be durable and explicit
RunState is not elegant theater. It is operational truth. Because approval, current step, artifacts, and prior outcomes are stored explicitly, the system can pause and resume without improvising.
3. Tool contracts belong in application code
Tool, ToolRegistry, and default_registry() make the available actions visible and reviewable. The risky flag on finalize_report shows the start of a policy boundary.
4. Traces are not a luxury add-on
The .runs/<run_id>/trace.json artifact means failed runs are diagnosable. That matters more than prompt cleverness once real side effects appear.
5. Provider optionality is healthier than provider centrality
The harness works in mock mode and can optionally use the repo-local OpenAI-compatible endpoint. That lets the system remain runnable and testable even when external model behavior is noisy.
What it still does not solve
The anatomy is solid for a demo, but it has clear limits.
1. The workflow is a hand-written linear state machine
That is fine here, and arguably better than premature graph complexity. But it does mean alternate branches, compensating actions, and richer orchestration policies are still manual.
2. Tool schemas are descriptive, not enforced
input_schema in Tool is informative, but the repo is not yet validating tool inputs or outputs with a runtime schema system. That becomes more important as tool count rises.
3. Approval policy is binary and local
The harness can pause before a risky write, but it does not yet support richer policies like role-based authorization, multiple approval classes, environment-specific restrictions, or sandbox enforcement.
4. Reviewer output handling is brittle
The current review_markdown() path expects clean JSON from the model. Real providers frequently return fenced JSON or extra prose. The verified failure in this run shows that the repo still needs more robust structured-output handling.
5. Persistence is local-only
Saving runs under .runs/ is excellent for clarity and local durability, but it is not a distributed execution substrate. There is no external datastore, leasing, queueing, or multi-worker coordination.
6. Observability is file-based, not platform-grade
The traces are useful, but there is no metrics backend, no dashboarding, no span correlation, and no evaluation harness tied into trace replay yet.
Why this anatomy is more important than most agent marketing
The industry spends a lot of energy on labels like autonomous agent, multi-agent architecture, AI workflow platform, and MCP-native runtime. Those terms are not useless, but they blur the engineering questions that actually matter.
When a run fails, can you inspect it? When a risky action is pending, can you prove the system is waiting? When a tool misbehaves, can you see the attempt count and artifact state? When a provider returns malformed structure, do you get a visible failure mode instead of a ghost story?
This repo gives good answers to those questions precisely because its anatomy is plain.
Before talking about MCP adapters, richer orchestration, durable execution upgrades, or policy engines, it helps to identify the minimum organs of a useful harness. In this demo, those organs are already there:
- command surface
- state model
- runner
- tool contracts
- persistence
- traces
- provider boundary
- review boundary
- approval gate
You can argue about implementation details. You can extend every one of them. But if one of those organs is missing entirely, the system is usually still in demo land.
What changed in the repo for this post
No repo code changed for this article. The current public baseline was sufficient for an anatomy post.
That said, verification for this run surfaced a meaningful limitation in the existing code: the reviewer path in src/harness_engineering/reviewer.py is currently too strict about raw JSON-only responses from the local model. I am documenting that limitation here rather than pretending the run succeeded cleanly. That issue is likely worth addressing before a later post leans harder on model-backed review behavior.
The practical takeaway
If you are building an agent system and cannot quickly point to:
- where run state lives
- how approvals are represented
- how traces are recorded
- how tool contracts are defined
- how failures are resumed or diagnosed
then you probably do not have a harness yet. You have an agent-shaped demo.
The good news is that the anatomy does not need to be massive before it becomes useful. This repo proves that a few carefully separated files can already buy you clarity, durability, and operational honesty.
That is the shift. Not “make the prompt smarter.” Make the runtime legible.
References
- 67 AI Lab,
harness-engineeringrepository: https://github.com/67ailab/harness-engineering - Model Context Protocol Specification (2025-06-18): https://modelcontextprotocol.io/specification/2025-06-18
- OpenAI API docs, “Using tools”: https://developers.openai.com/api/docs/guides/tools
- Anthropic API docs, “Messages”: https://docs.anthropic.com/en/api/messages