The live demo repo for this series is 67ailab/harness-engineering, and for this post I did change the repo before publishing. The new capability shipped in commit d20e352, which adds an explicit memory-layer model to the demo instead of treating every stored value as one blurry thing called “memory.”
The core addition is src/harness_engineering/memory.py, plus wiring in src/harness_engineering/store.py and src/harness_engineering/cli.py so every run now emits a memory.json snapshot and the CLI exposes a memory command.
That matters because “memory” is one of the most overloaded words in agent systems. People use it to mean at least four different things:
- the prompt context sent to the model right now
- chat or thread history across turns
- durable workflow state for pause/resume
- retrieved knowledge from documents or prior runs
Those are not the same problem. If you collapse them into one bucket, your architecture gets confused fast.
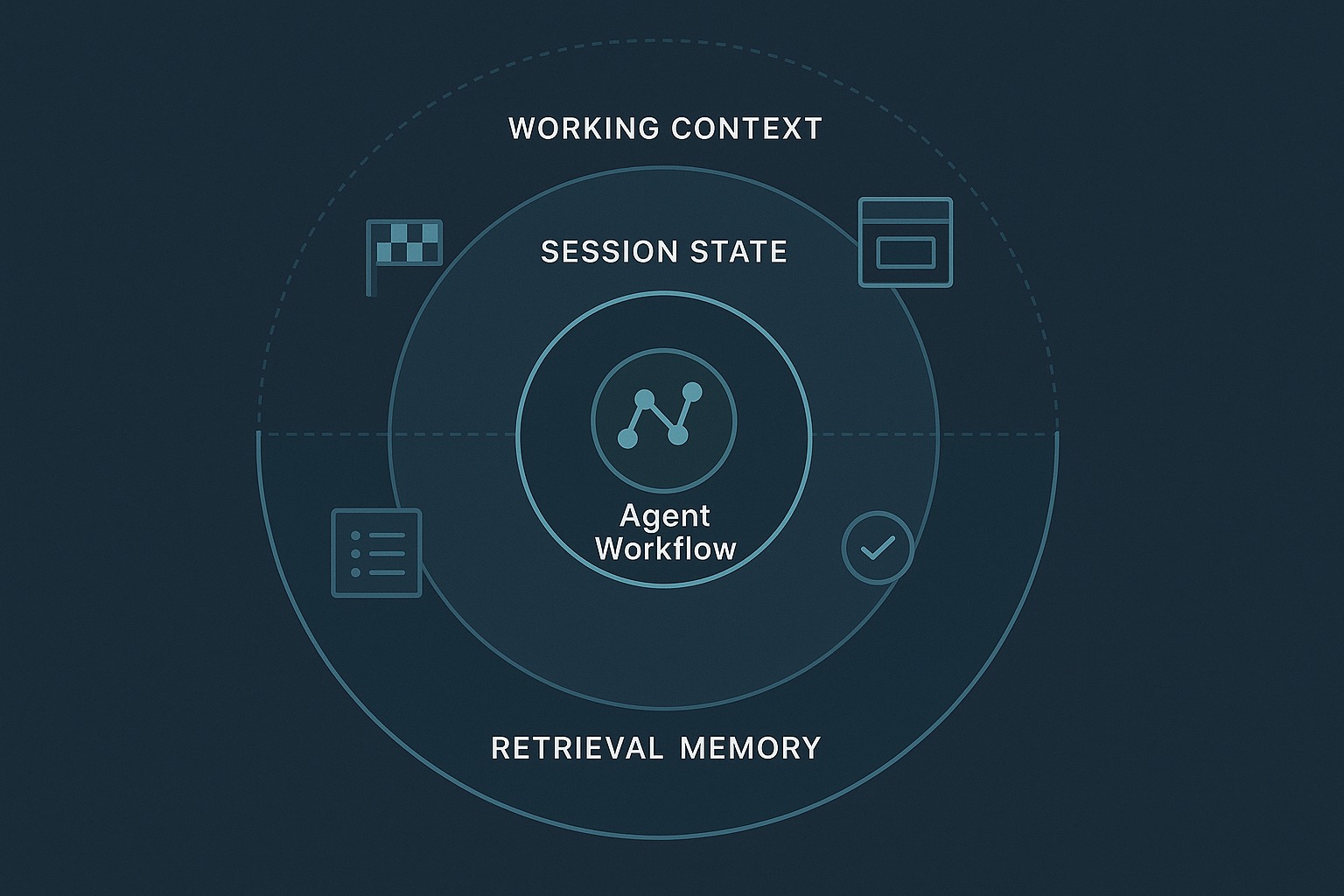
My practical claim in this post is simple: agent memory is not one store. It is at least three different engineering concerns with different failure modes: working context, session state, and retrieval memory.
The harness-engineering repo now demonstrates that separation directly.
What changed in the repo since the previous post
Post 5 focused on durable execution and added summary.json, trace history inspection, and CLI commands for summary and history.
For Post 6, the repo needed a memory model that made a sharper distinction between:
- what the runner needs right now
- what the system must persist across interruption
- what can be looked up on demand
So I added a new module: src/harness_engineering/memory.py.
The key functions are:
build_working_context(state)build_session_state(state)retrieve_memory(state, query, top_k)build_memory_snapshot(state, query, top_k)
Then RunStore.save() in src/harness_engineering/store.py was extended to write a per-run memory.json file next to state.json, trace.json, and summary.json. RunStore.memory_path() and the summary payload now expose that path. And src/harness_engineering/cli.py gained a new memory subcommand:
PYTHONPATH=src python3 -m harness_engineering.cli memory --latest
PYTHONPATH=src python3 -m harness_engineering.cli memory --latest --query "approval state" --top-k 3
I also updated README.md and added tests in tests/test_harness.py to verify that:
- the snapshot contains separate layers
- retrieval returns matching entries
memory.jsonis persisted on save- the CLI command works
That is a small repo change by line count, but it clarifies the whole architecture.
Why “memory” is such a bad umbrella term
LangGraph’s memory docs make a useful first cut: short-term memory is thread-scoped state, while long-term memory is cross-session data recalled later from a store. The OpenAI Agents SDK session docs make another useful distinction: session memory is the stored conversation history that gets prepended between runs. Temporal’s workflow docs make a different but equally important distinction: workflow recovery depends on durable event history and replay-safe state reconstruction, not vague “memory.”
Those systems differ in design, but they agree on one thing: you should not pretend that all remembered information is the same kind of thing.
In practical harness design, I think the minimum useful split is this:
1. Working context
This is the small slice of information the next step needs right now.
It should be:
- current
- bounded
- cheap to assemble
- intentionally pruned
If it grows without discipline, latency rises, cost rises, and model quality usually drops.
2. Session state
This is the durable state of the run itself.
It should answer questions like:
- What run is this?
- What step is it on?
- Is approval pending?
- What artifacts already exist?
- What trace events already happened?
This is the state you need for pause/resume, auditing, inspection, and operations.
3. Retrieval memory
This is not always “memory” in the human sense. Often it is just a searchable pool of relevant material that can be fetched when needed.
It should be:
- queryable
- relevance-ranked
- optional to pull into the working context
- separable from durable workflow state
The repo now models those three layers explicitly.
Where the three layers live in the current demo
The durable run model is still RunState in src/harness_engineering/models.py. That is the backbone of the harness. It holds fields like:
run_idstatuscurrent_steprequires_approvalapprovedpending_actionplansource_documentsartifactstracestep_results
But RunState itself is not yet a good explanation of memory architecture. It is just the raw data model.
The explanation now lives in src/harness_engineering/memory.py.
Working context: build_working_context()
build_working_context(state) extracts the minimum operator-visible context for the next execution moment:
topiccurrent_stepstatusrequires_approvalpending_actionplan_outline- a preview of extracted facts
- a compact preview of the draft markdown
- review pass/fail state
That is intentionally not everything in the run. It is the “what matters right now” layer.
In other words: this is the layer you might actually hand to a model or an operator before the next step.
Session state: build_session_state()
build_session_state(state) is the opposite. It is not trying to be small; it is trying to be durable and legible.
It includes:
- run metadata
- approval flags
- the full plan outline
- artifact keys
- a compact list of prior
step_results - counts of trace events
last_error
This is the layer that makes pause/resume explainable.
It lines up naturally with the rest of the durable execution code in:
HarnessRunner.run_until_pause_or_complete()insrc/harness_engineering/runner.pyHarnessRunner.approve()HarnessRunner.resume()RunStore.save()insrc/harness_engineering/store.py
The session-state layer is what lets the repo treat approval as workflow state instead of chat etiquette.
Retrieval memory: retrieve_memory()
retrieve_memory(state, query, top_k) is the most important conceptual addition.
It searches over two things already present in the run:
state.source_documents- extracted facts under
state.artifacts["facts"]
This is deliberately simple. There are no embeddings, no vector database, and no external retrieval service yet. Matching is just lightweight token overlap. But the architectural point still lands: retrieval memory is fetched by query instead of shoved wholesale into the working context.
That distinction matters more than the sophistication of the ranking algorithm.
In a real system, this layer might be backed by:
- a vector store
- BM25 or hybrid search
- a profile store
- a document namespace
- prior-run trace summaries
- external knowledge bases
The demo does not have those yet. Good. It keeps the interface visible.
A real run that shows the separation
I ran the updated repo locally after adding the new memory layer.
First I verified model connectivity using the repo’s preferred local-provider setup:
cd /home/james/.openclaw/workspace/harness-engineering
PYTHONPATH=src python3 -m harness_engineering.cli doctor
That succeeded against the configured OpenAI-compatible endpoint with:
- provider:
openai_compatible - model:
gemma4 - status:
ok - message:
MODEL_OK
Then I ran the harness and inspected memory:
HARNESS_MODEL_PROVIDER=mock PYTHONPATH=src python3 -m harness_engineering.cli start \
--topic "memory architecture for approval-gated agent harnesses" \
--source-file sample_data/sources.json
HARNESS_MODEL_PROVIDER=mock PYTHONPATH=src python3 -m harness_engineering.cli memory --latest \
--query "approval state" --top-k 3
The output is exactly the kind of thing I want from a teaching repo.
The working_context layer showed:
- the topic
current_step- current run
status - a short facts preview
- a compact preview of the generated markdown
- review status
The session_state layer showed:
- durable run identifiers and timestamps
- approval booleans
- artifact keys
- compact step results
- trace event counts
The retrieval_memory layer returned only the entries relevant to the query approval state, including both extracted facts and source documents.
That is the point. The operator does not have to pretend every remembered thing belongs in one list.
The subtle but important design rule
The best way to say this is bluntly:
Do not use your durable session state as your model context window.
That mistake is everywhere.
If you pour all run metadata, traces, old tool outputs, documents, and user history into one growing prompt, you get the worst of all worlds:
- token bloat
- degraded model attention
- fragile prompt construction
- unclear audit boundaries
- poor operator ergonomics
The new repo structure resists that.
RunState remains the source of durable truth for execution. build_working_context() constructs a narrow operational slice. retrieve_memory() pulls relevant material only when asked. That is a healthier architecture than “the model can see everything.”
Where this aligns with broader agent tooling
LangGraph’s memory model is helpful here because it separates thread-scoped state from long-term stores. That is close to the split between working/session state and retrieval memory in this repo, even though the implementation is much lighter.
The OpenAI Agents SDK sessions docs are helpful for a different reason: they make session history a first-class runtime concern rather than something the developer manually reassembles each turn. That is the same instinct behind the repo’s session_state layer, even though this demo is not a chat agent.
Temporal is useful as the stricter systems reference point. Temporal’s workflow docs emphasize that event history is the source of truth and that replay-safe recovery is not the same thing as restoring a vague snapshot. That matters here because the repo’s session-state layer is useful, but it is still not full deterministic replay.
That distinction is worth keeping clear:
- this repo now demonstrates memory-layer separation
- it already demonstrated checkpointed pause/resume
- it still does not implement Temporal-style replay semantics
That is fine. Honest scope is a strength.
What the demo proves
The updated repo proves a few things clearly.
1. “Memory architecture” can be demonstrated without a giant framework
You do not need a massive orchestration platform to make the distinctions visible. A small local harness with explicit functions is enough.
2. Working context and durable session state are different layers
build_working_context() and build_session_state() are small functions, but they make a big conceptual correction. The data you need to operate the workflow is not the same as the data you should stuff into the next model call.
3. Retrieval memory is best treated as an explicit query surface
Even with simple lexical matching, retrieve_memory() demonstrates the right interface boundary: ask for relevant items when needed instead of serializing everything into the run context.
4. Memory architecture becomes much easier to inspect when persisted
Because RunStore.save() now writes memory.json, the three-layer view survives process exit just like state.json, trace.json, and summary.json do.
That is small, but operationally useful.
What it still does not solve
This section matters more than the flashy one.
1. Retrieval is still primitive
retrieve_memory() uses simple token overlap on in-run documents and facts. There is no embedding index, hybrid retrieval, namespace isolation, or recency weighting.
2. The demo does not yet separate cross-run long-term memory from per-run retrieval
Right now retrieval works over source_documents and extracted facts attached to a run. That is useful, but it is not the same thing as a cross-session memory store.
3. Working-context budgeting is still crude
The repo now exposes the concept, but it does not yet measure token budgets or automatically compress context based on model constraints.
4. Reviewer robustness is still weak on the local-model path
This is a real observed limitation from the live repo. During a local-model run, review_markdown() in src/harness_engineering/reviewer.py still failed when the reviewer returned fenced JSON instead of raw JSON. The harness correctly exposed that failure in the saved memory and state, but it did not gracefully recover from it.
5. This is not a full memory operating system for agents
There is no user-profile layer, no episodic memory store across runs, no semantic recall over large corpora, and no background memory-writing pipeline.
Again: that is fine. The repo is a teaching system, not a claims machine.
The practical engineering takeaway
If your agent system has a single field called memory and you keep pouring more things into it, you probably have an architecture problem.
Ask three separate questions instead:
- What does the next step need right now?
- What must survive interruption and remain operator-visible?
- What can be looked up only when relevant?
If you answer those separately, your harness gets better almost immediately:
- prompts shrink
- pause/resume becomes clearer
- audits get easier
- retrieval gets more disciplined
- the system becomes easier to extend
That is why this repo change was worth making before publishing the post. The concept now exists as real code rather than blog abstraction.
The repo still has a long way to go. It should eventually add token-budget accounting, stronger retrieval, and maybe a true cross-run memory store. But the architecture is better now because it stopped pretending memory is one thing.
That is the useful lesson.
References
- 67 AI Lab,
harness-engineeringrepository: https://github.com/67ailab/harness-engineering - LangGraph documentation, “Memory overview”: https://docs.langchain.com/oss/python/concepts/memory
- OpenAI Agents SDK documentation, “Sessions”: https://openai.github.io/openai-agents-python/sessions/
- Temporal documentation, “Workflows”: https://docs.temporal.io/workflows