The live demo repo for this series is 67ailab/harness-engineering, and for this post I did change the repo before publishing. The new capability shipped in commit dadf203, which adds a small but real multi-agent mode to the demo: the harness can now run with explicit planner, executor, and reviewer roles, persist role activity, record handoffs, and expose those artifacts through the CLI and saved run files.
The core changes are in:
src/harness_engineering/multi_agent.pysrc/harness_engineering/runner.pysrc/harness_engineering/cli.pysrc/harness_engineering/models.pysrc/harness_engineering/store.pysrc/harness_engineering/tracing.pysrc/harness_engineering/memory.pytests/test_harness.pyREADME.md
I care about this topic because most “multi-agent” writing is still too theatrical. You get diagrams full of specialist agents, manager agents, critic agents, verifier agents, memory agents, routing agents, and somehow a meta-agent above all of them. It sounds impressive right up until you ask basic engineering questions:
- What is the contract between these agents?
- Where does one role end and another begin?
- Which handoff is persisted?
- What happens when review fails?
- What state survives pause and resume?
- What makes this better than a single loop with clear steps?
That last question is the important one.
My argument in this post is simple: multi-agent systems become useful when roles are sharp, handoffs are explicit, and the runtime keeps the system honest. If you cannot inspect the role boundaries, you probably do not have a meaningful multi-agent system yet. You have a prompt pattern wearing a costume.
This repo now demonstrates a version of multi-agent that I actually trust enough to discuss: small, traceable, approval-gated, and modest about what it is.
What changed in the repo since the previous post
Post 9 added a harness-level policy boundary. The demo learned to classify actions, deny writes outside allowed roots, and persist policy decisions in traces and summaries.
That was an important prerequisite for Post 10, because a useful multi-agent story is not just “split the work.” It is “split the work without losing control.”
The series plan for Post 10 called for a planner/reviewer split in the repo. Before this run, the demo technically had planning and review functions:
create_plan_from_env()insrc/harness_engineering/reviewer.pyreview_from_env()insrc/harness_engineering/reviewer.py
But those were helper calls inside a single runner. They did not create explicit role activity, they did not persist handoff artifacts, and they did not expose an inspectable multi-agent surface.
That meant the repo did not yet justify a serious post called “Multi-Agent Systems Without the Theater.”
So I added a real, if intentionally small, multi-agent variant.
The design choice: small roles, not a fake swarm
The design is intentionally conservative.
I did not turn the demo into a graph runtime. I did not add parallel branches. I did not invent a manager-of-managers. I did not claim emergent collaboration.
Instead, the repo now supports two run modes:
singlemulti_agent
That state is stored directly on RunState in src/harness_engineering/models.py:
run_mode: str = "single" # "single" or "multi_agent"
And RunState.new() now accepts run_mode, so the mode becomes part of durable run state instead of an ephemeral CLI flag.
That is the right first step. If you want to discuss multi-agent behavior seriously, the run itself needs to know which mode it is in.
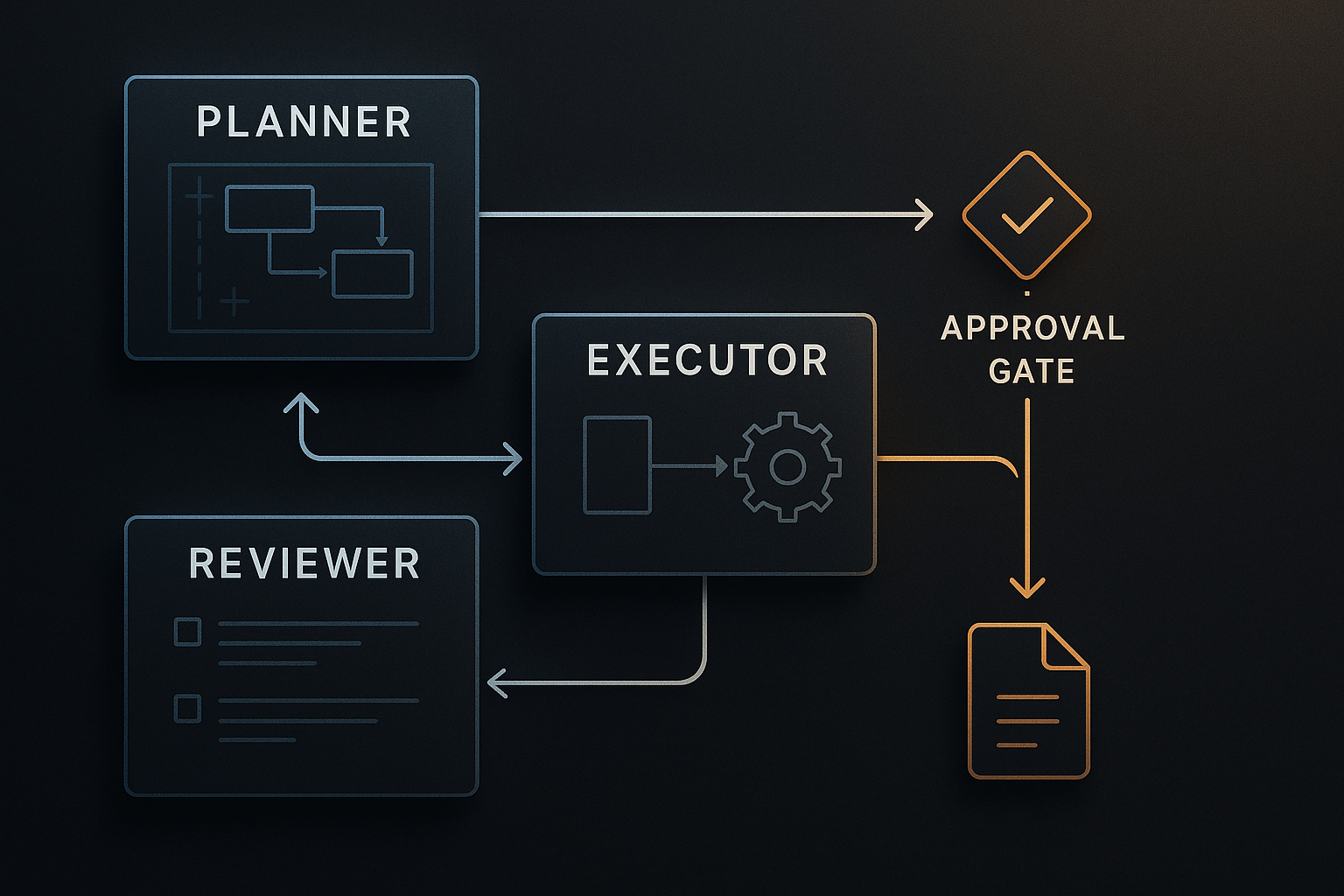
The new explicit role layer
The new file src/harness_engineering/multi_agent.py contains the small role boundary for this repo.
The key functions are:
planner_step(topic, source_documents)reviewer_handoffs(topic, markdown, facts, review)build_handoff(from_role, to_role, purpose, payload)build_multi_agent_snapshot(handoffs)
The important thing is not the amount of code. It is the shape of the interface.
planner_step()
planner_step() still uses the existing planning machinery under the hood through create_plan_from_env(), but it now packages the result as a role-scoped artifact:
- planner role name
- provider used
- goal
- source document titles
- step count
- plan outline
Then it creates a concrete handoff from planner to executor with:
from_roleto_rolepurposepayload- timestamp
That is exactly the sort of thing most multi-agent demos skip. They say a planner handed work to an executor, but they do not store the handoff as a first-class artifact.
reviewer_handoffs()
The review side follows the same rule.
The repo now records two explicit review handoffs:
executor -> reviewerreviewer -> executor
The inbound handoff contains a draft preview and fact count. The outbound handoff contains the review decision:
passedfindingsreviewer
So the reviewer is no longer just a hidden function call in the middle of the runner. In multi-agent mode, it becomes an explicit role boundary with a persisted input/output exchange.
That is the whole point of the feature.
Where the real orchestration still lives
The actual runtime still lives in src/harness_engineering/runner.py, inside HarnessRunner.
That matters because I do not want to mislead readers. This is not a second orchestration engine. It is the same harness with a different, more inspectable role model.
The central method is still:
HarnessRunner.run_until_pause_or_complete(state)
And the runner still advances through the same core steps:
search_mockextract_factsdraft_reportfinalize_report
What changes in multi_agent mode is the metadata and trace layer around those steps.
New runner methods for role recording
HarnessRunner now has two important helpers:
_record_role_activity(...)_record_handoff(...)
_record_role_activity() persists a role execution record into state.artifacts["role_executions"] and also emits a role_activity trace event.
_record_handoff() appends to state.artifacts["handoffs"], refreshes state.artifacts["multi_agent"] using build_multi_agent_snapshot(...), and emits a role_handoff trace event.
That combination is what makes the new mode real.
Without those methods, “multi-agent” would still just be an internal storytelling device. With them, the run stores the actual role boundaries it claims to use.
How the runner behaves in multi_agent mode
The branching happens in two places.
1. create_run(...)
In HarnessRunner.create_run(...), the repo now does this conceptually:
- create a run with
run_mode - if
run_mode == "multi_agent":- call
planner_step(...) - store
planner_packet - record planner role activity
- record planner → executor handoff
- emit
run_createdwithmode="multi_agent"
- call
- otherwise use the existing single-run planner path
So the planner role is explicit from the first moment the run exists.
2. run_until_pause_or_complete(...)
Inside run_until_pause_or_complete(...), multi-agent mode records role activity before each executor-owned step:
- executor runs
search_mock - executor runs
extract_facts - executor runs
draft_report
Then the runner performs review with review_from_env(...), but in multi-agent mode it also builds explicit reviewer handoffs through reviewer_handoffs(...) and records reviewer role activity.
This is a good design choice, in my opinion. The repo keeps one real source of review truth while still making the role exchange visible.
That helps avoid a classic multi-agent failure mode: duplicating logic just to make the architecture diagram look more impressive.
The new CLI surface
This feature would be much less useful without inspection surfaces.
The CLI now supports:
PYTHONPATH=src python3 -m harness_engineering.cli start \
--topic "..." \
--source-file sample_data/sources.json \
--multi-agent
And it exposes a dedicated inspection command:
PYTHONPATH=src python3 -m harness_engineering.cli handoffs --latest
The handoffs command in src/harness_engineering/cli.py prints:
run_idrun_modecurrent_rolehandoff_countrole_execution_count- full
handoffs - full
role_executions
That is exactly the sort of operator-facing view I want in a practical multi-agent harness. Not a marketing diagram. A concrete inspection command.
Persisted artifacts: the part that makes this worth discussing
RunStore in src/harness_engineering/store.py now writes a new artifact:
.runs/<run_id>/handoffs.json
The saved file includes:
run_idrun_modehandoffsrole_executions
At the same time, build_summary(state) now includes a compact multi_agent block with:
enabledhandoff_countcurrent_roleroles_seen
And build_trace_summary(state) in src/harness_engineering/tracing.py now includes:
handoff_countrole_activity_by_rolehandoff_pairscurrent_role
That is the most important engineering move in this change set.
A multi-agent architecture only becomes operationally meaningful when the handoffs are visible in persisted state, summaries, and traces.
A real run from the live repo
Before writing this post, I verified the repo in /home/james/.openclaw/workspace/harness-engineering.
I ran the required checks:
make check
PYTHONPATH=src python3 -m harness_engineering.cli doctor
Those passed.
make checkpassed, including the secret scan.doctorreturnedstatus: okagainst the repo-local OpenAI-compatible endpoint using modelgemma4athttp://192.168.0.16:8080/v1.
I also ran a clean multi-agent demo outside the repo root so it would use the mock provider instead of repo-local .env, which makes the resulting behavior easier to reproduce.
That run created:
- run ID:
ee238681-bb50-4db2-8e16-bc989c59e191 - run mode:
multi_agent - status:
waiting_approval - current step:
finalize_report
The saved handoffs.json contained exactly three handoffs:
planner -> executorexecutor -> reviewerreviewer -> executor
And the payloads were not placeholders. They included real summaries:
- the planner handoff carried a 4-step plan and source document titles
- the executor-to-reviewer handoff carried a fact count and draft preview
- the reviewer-to-executor handoff carried
passed: true,findings: [], andreviewer: "mock"
The same run’s trace_summary.json showed:
trace_events: 21role_activity: 5role_handoff: 3policy_checked: 4tool_ok: 3- latest event
approval_required multi_agent.handoff_pairsof:planner->executor: 1executor->reviewer: 1reviewer->executor: 1
That is enough for me to call the feature real.
Not because it is complicated. Because it is inspectable.
Why this is better than most multi-agent demos
A lot of agent systems get more fragile as soon as they become “multi-agent,” because the role split is only conceptual. There is no durable contract.
This repo now makes three practical choices that keep the design grounded.
1. Roles are few
There are three roles:
- planner
- executor
- reviewer
That is enough to illustrate the pattern without inventing needless specialization.
2. The handoffs are explicit
The handoffs are not just implied by function call order. They are materialized as data structures and saved as artifacts.
3. The harness still owns the risky boundaries
This is important. Multi-agent mode does not bypass the existing harness controls.
The same policy logic still applies in HarnessRunner._execute(...).
The same approval gate still applies before finalize_report writes to disk.
That is the right architecture.
You do not want role decomposition to weaken the runtime boundary. You want the runtime boundary to stay central while the role model becomes more legible.
What the demo proves
1. A useful multi-agent system can be small
This repo proves that you do not need a swarm to get value from multiple roles. A planner, an executor, and a reviewer are enough to create meaningful role separation.
2. Handoffs should be persisted, not imagined
The new handoffs.json artifact and the summary/trace surfaces prove the most important point in the post: multi-agent claims become more credible when the handoffs are stored and inspectable.
3. Multi-agent and harness discipline are compatible
The repo did not sacrifice approvals, policy checks, or resumable state to add role structure. The multi-agent mode stays inside the same approval-gated, policy-checked harness.
4. Review is more useful when it returns to the runtime, not to the hype
The explicit reviewer -> executor handoff makes the architecture clearer: review is not a vibe, it is a decision that the runtime consumes before moving to a risky write step.
What it still does not solve
This part matters more than the happy path.
1. This is not parallel execution
The roles are explicit, but the runtime is still linear. There is no concurrent execution, no branch scheduling, and no graph runtime.
2. The planner and reviewer are still lightweight wrappers around existing helper functions
That is deliberate. It keeps the demo honest. But it also means the repo is showing role separation, not deep specialization with different tool sets or isolation boundaries per role.
3. There are no per-role permissions yet
The harness still has one shared policy model. It does not yet express role-specific capability boundaries such as “reviewer cannot request writes” or “planner cannot access filesystem tools.”
4. There is no negotiation or arbitration layer
If planner output is poor, the executor still follows the same small workflow. If reviewer output fails, the run fails. There is no retry negotiation between agents, no scoring arbitration, and no long-lived debate loop.
5. The local-model reviewer path still has real-world brittleness
During implementation, I hit a real issue: the local reviewer could return fenced JSON instead of raw JSON, which caused the review step to fail. That bug is part of why I think persisted handoffs matter. In a more theatrical system, it would be easy to miss where the failure actually happened.
Relation to the broader ecosystem
This repo is still a tiny local demo, but it maps cleanly to the bigger infrastructure conversation.
The MCP spec is useful because it standardizes how tools and capabilities can be exposed across hosts, clients, and servers. But MCP by itself does not decide how many agents you should have, what their contracts should be, or how handoffs should be persisted. That is harness work.
LangGraph is useful because it focuses on orchestration concerns like durable execution, persistence, streaming, and human-in-the-loop control. That is closer to the right abstraction level for serious agent systems than “just add more agents.”
The OpenAI Agents SDK is useful because it treats handoffs and guardrails as first-class runtime primitives rather than as pure prompt composition. That is one of the few mainstream API surfaces that at least points in the same direction as this post.
And Temporal remains a useful mental model because durable workflow systems force you to think in terms of explicit state progression, replay, and recoverable execution. Whether or not you use Temporal itself, that habit is healthy for agent harness design.
The pattern across all of them is the same: the runtime matters more than the cast list.
The practical rule I would use
If you are considering a multi-agent design, ask these questions before you add another role:
- What unique responsibility does this role own?
- What artifact does it hand off?
- What does success or failure look like at that boundary?
- How will you inspect that handoff later?
- Could the same result be achieved more simply inside one well-instrumented loop?
If you cannot answer those questions, do not add the agent.
That rule sounds conservative. Good. Conservatism is underrated in agent engineering.
In my experience, a single well-built harness beats a theatrical multi-agent diagram most of the time. And when you really do need multiple roles, the useful version is usually boring:
- clear role names
- explicit handoffs
- persisted state
- strict approvals
- honest limitations
That is what this repo now demonstrates.
Not a society of minds. Just a small system that tells the truth about its own structure.
References
- 67 AI Lab,
harness-engineeringrepository: https://github.com/67ailab/harness-engineering - Model Context Protocol specification (2025-03-26): https://modelcontextprotocol.io/specification/2025-03-26
- LangGraph overview: https://docs.langchain.com/oss/python/langgraph/overview
- OpenAI Agents SDK documentation: https://openai.github.io/openai-agents-python/
- Temporal documentation, “Workflow Execution”: https://docs.temporal.io/workflow-execution