The live demo repo for this series is 67ailab/harness-engineering, and for this post I did change the repo before publishing. The new repo commit is 7d01dae, which adds a real blueprint export to the demo so the architecture in this article is not just a hand-drawn diagram in prose. You can now run:
PYTHONPATH=src python3 -m harness_engineering.cli blueprint --pretty
PYTHONPATH=src python3 -m harness_engineering.cli blueprint --format markdown
PYTHONPATH=src python3 -m harness_engineering.cli blueprint --format mermaid
That feature lives mainly in:
src/harness_engineering/blueprint.pysrc/harness_engineering/cli.pyREADME.mdtests/test_harness.py
And it builds on the rest of the repo’s already-shipped architecture:
src/harness_engineering/runner.pysrc/harness_engineering/tools.pysrc/harness_engineering/policy.pysrc/harness_engineering/store.pysrc/harness_engineering/tracing.pysrc/harness_engineering/memory.pysrc/harness_engineering/workflow.pysrc/harness_engineering/mcp.pysrc/harness_engineering/multi_agent.py
This is the right moment in the series to stop talking about isolated features and show the whole machine.
A lot of agent writing still jumps from one capability to another: tool calling, memory, approval, evals, multi-agent, safety, cost. That is useful up to a point. But production work eventually needs a reference answer to a simpler question:
What does a sane agent harness actually look like when you put the pieces together?
Not a benchmark prompt. Not a slide with six boxes labeled “planner,” “worker,” and “critic.” A runtime blueprint you can point to, inspect, run, and argue with.
That is what this post is about.
What changed in the repo since the previous post
Post 12 added better performance and cost rollups to traces and summaries. That made the harness easier to operate, but it still left one gap: the repo had architecture, but it did not yet have an architecture artifact.
A reader could inspect the code and infer the blueprint. An operator could run the CLI and inspect the artifacts. But the repo did not provide a first-class, exportable view of its own structure.
So for Post 13 I added exactly that.
The key function is build_reference_blueprint() in src/harness_engineering/blueprint.py. It composes a runtime-level architecture document from live code surfaces:
- the tool registry from
default_registry()insrc/harness_engineering/tools.py - the workflow graph from
build_workflow_definition()insrc/harness_engineering/workflow.py - the effective policy view from
PolicyEngine.describe()insrc/harness_engineering/policy.py - the persisted artifact model from
RunStore - the known runtime limitations of this demo
Then cmd_blueprint() in src/harness_engineering/cli.py exports that view as JSON, Markdown, or Mermaid.
That may sound small. I think it is actually an important threshold. Once a harness can export its own reference blueprint, you are no longer relying on repo folklore. The runtime can explain itself.
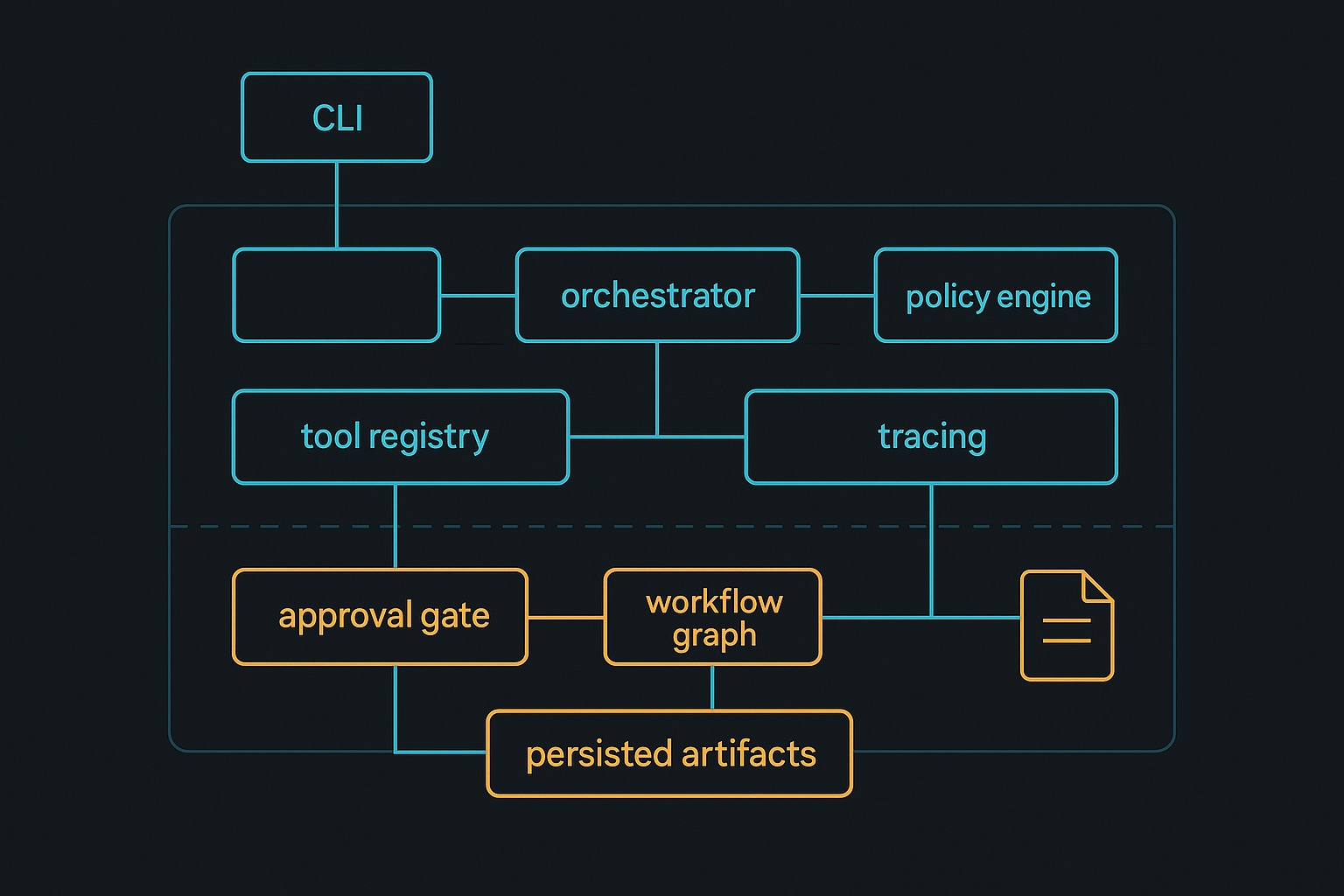
The blueprint starts with the control plane, not the model
The most important architectural choice in this repo is also the thesis of the whole series: the model is not the system.
The control plane in this harness is made of several explicit layers:
- CLI surface in
src/harness_engineering/cli.py - Execution runtime in
HarnessRunnerinsidesrc/harness_engineering/runner.py - Typed tool registry in
src/harness_engineering/tools.py - Policy boundary in
src/harness_engineering/policy.py - Persistence layer in
RunStoreinsidesrc/harness_engineering/store.py - Trace and summary layer in
src/harness_engineering/tracing.py - Memory-layer separation in
src/harness_engineering/memory.py - Workflow definition export in
src/harness_engineering/workflow.py
The actual model call is just one tool path: draft_report() in src/harness_engineering/tools.py, which delegates to build_report_markdown() and provider wiring in src/harness_engineering/provider.py.
That is exactly how I think a practical harness should be shaped. The model is a component inside a controlled runtime, not the runtime itself.
The runtime loop is still the center of gravity
If I had to point to one class as the center of the demo, it is still HarnessRunner in src/harness_engineering/runner.py.
The key methods are:
create_run()run_until_pause_or_complete()_execute()_estimate_step_metrics()approve()resume()
This is where the repo makes its strongest architectural statement.
The harness is not “the model plus tools.” The harness is the loop that:
- decides the next step
- checks policy before execution
- records trace events
- persists state after meaningful transitions
- pauses for approval before risky actions
- resumes without losing context
- turns tool outputs into durable operator artifacts
That is why I think a good reference blueprint should revolve around runtime control points, not around prompt templates.
Temporal’s documentation is useful here as a contrast and a north star. Their workflow model emphasizes durable execution, replay, and resumability as first-class runtime properties, not as afterthoughts attached to business logic. This repo is not Temporal. It does not claim to be. But it clearly moves in that direction conceptually: execution state is persisted, replay-adjacent artifacts exist, approval pauses are explicit, and resume is part of the runtime contract rather than a hack around chat history.1
Typed tools matter, but the schema layer is only one layer
Earlier in the series I argued that tool calling and MCP matter, but they do not solve orchestration by themselves. Post 13 makes that easier to explain.
The repo has a clean schema/export layer in src/harness_engineering/mcp.py:
tool_to_mcp_descriptor()registry_to_mcp_tools()validate_tool_arguments()call_tool_mcp()
That gives the harness a provider-neutral way to describe tools and invoke them through a standard-shaped interface. The MCP spec is valuable for exactly this reason: it standardizes how hosts, clients, and servers expose tools, resources, and related capabilities over a JSON-RPC-based protocol.2
But the blueprint export makes the next point obvious:
MCP is not the whole architecture.
The repo still needs all of these layers around that schema surface:
- policy checks before risky execution
- state persistence after transitions
- approval gating before writes
- trace summaries after steps
- memory views for operator inspection
- workflow exports for architecture clarity
In other words: standardized tool description is necessary, but it is not enough.
The persistence contract is what separates the harness from a demo script
The most production-shaped part of this repo is not the model client. It is RunStore in src/harness_engineering/store.py.
That class persists a run into a directory of machine-readable artifacts:
state.jsontrace.jsonsummary.jsontrace_summary.jsonmemory.jsonhandoffs.json- optionally
final_report.md
And it provides the operator-facing surfaces that matter:
build_summary()history()latest_run_id()- path helpers for every saved artifact
This is where a lot of “agent frameworks” still feel underbuilt to me. They are good at prompting, but weak at artifact discipline. If a run fails, pauses, or needs audit, you want files and explicit summaries. You do not want vibes.
The blueprint export now makes that persistence contract visible in one place. That is useful because architecture becomes easier to evaluate when the artifact model is explicit.
Memory is separated by purpose, not by marketing term
Another part of the blueprint I like is that memory is represented as layers rather than as one overloaded concept.
src/harness_engineering/memory.py exports:
build_working_context()build_session_state()retrieve_memory()build_memory_snapshot()
That separation is simple, but it is the right kind of simple.
The harness distinguishes between:
- working context: what the next step needs right now
- session state: durable run metadata for pause/resume/inspection
- retrieval memory: relevant source snippets and facts fetched on demand
I think this is a better reference pattern than the common “just give the agent memory” framing. Systems go sideways when working context, durable state, and retrieval are all mixed together under one vague abstraction.
Policy and approval are runtime primitives, not UI decoration
A lot of agents claim to be “human in the loop,” but what they really mean is that the model prints “Should I continue?” in chat.
This repo does something better.
PolicyEngine.evaluate() in src/harness_engineering/policy.py classifies actions and checks write targets. Then HarnessRunner._execute() enforces those decisions before a tool runs. For the risky write path, run_until_pause_or_complete() constructs pending_action_details, sets state.requires_approval, records the approval_required trace event, and stops before finalize_report writes anything.
That is the correct shape.
Approval is not text. Approval is state.
And because the blueprint export includes the policy description plus the persisted artifact model, a reader can see that approval lives in the runtime itself, not in a presentation layer bolted on top.
This lines up with the safety guidance in the MCP specification too: tool execution is powerful, descriptions should be treated cautiously, and users should explicitly consent to data access and tool invocation.2
Observability belongs in the architecture diagram
One thing I increasingly dislike in AI diagrams is that they treat observability as optional. The “real” system is shown in the boxes, and logs are some fuzzy thing off to the side.
The blueprint export in this repo does not do that. It includes tracing and summaries as named components because they are structural.
src/harness_engineering/tracing.py provides:
add_trace()build_trace_summary()
And those outputs are saved automatically by RunStore.save().
That is important. Observability is not merely a debugging feature. It is part of the runtime contract. If an agent system has no durable trace of its decisions, retries, approvals, role handoffs, and outputs, it is not mature enough to trust with operational work.
The same applies to performance. Post 12 added timing and lightweight token/workload estimates; Post 13 places those metrics in the broader reference architecture. OpenAI’s latency guidance is basically a runtime-design document when you read it with harness eyes: make fewer requests, parallelize when possible, generate fewer tokens, and do not default to an LLM where ordinary code will do.3 Those are blueprint concerns.
Multi-agent belongs in the blueprint, but only honestly
This repo’s multi-agent mode is included in the blueprint, but it is described carefully.
The relevant file is src/harness_engineering/multi_agent.py, especially:
planner_step()reviewer_handoffs()build_multi_agent_snapshot()
The exported blueprint explicitly notes that multi-agent mode is available, but that it keeps a small linear workflow and records planner/executor/reviewer handoffs rather than spawning a fake swarm.
Good.
That is the kind of honesty reference architecture needs. A blueprint should not exaggerate sophistication. It should show where the boundaries actually are.
What the demo proves
First, it proves that a usable agent harness can be built as a collection of explicit runtime layers rather than as one giant model wrapper.
Second, it proves that a reference architecture can be exported from live code. In this repo, the architecture is not just described in README.md; it is generated through build_reference_blueprint() and surfaced through cmd_blueprint().
Third, it proves that the most important parts of an agent system are inspectable when you engineer them directly:
- tool contracts
- action categories
- policy decisions
- workflow states and transitions
- approval gates
- durable artifacts
- trace summaries
- memory layers
- role handoffs
Fourth, it proves that a small harness can point toward production ideas without pretending to be a full workflow platform. That restraint matters.
What it still does not solve
This demo is still a local Python harness, not a production control plane.
It does not provide:
- distributed scheduling
- remote workers or queue-backed execution
- true deterministic replay semantics
- provider-accurate billing and token accounting
- OS-level sandboxing or network isolation
- robust concurrency control across many simultaneous runs
- formal schema versioning for persisted state
- large-scale secrets management
And the new blueprint export does not magically solve those things either. It just makes the current boundaries explicit.
That is still valuable. A blueprint should clarify what exists and what does not.
The reference pattern I would actually carry forward
If I were extending this repo toward a more production-grade system, I would preserve the current shape.
I would keep:
- a narrow CLI and control surface
- a runtime class like
HarnessRunneras the orchestrator boundary - a typed tool registry with explicit action categories
- a policy engine independent of the model provider
- a first-class persisted artifact store
- trace and summary generation on every meaningful transition
- clear separation between working context, durable session state, and retrieval memory
- explicit approval as workflow state
Then I would evolve the underlying durability and isolation story: stronger replay semantics, queue-backed execution, better provider accounting, better sandboxing, and versioned state schemas.
That is why I think “reference blueprint” is a better frame than “agent framework.” It forces the right question: which runtime responsibilities are already explicit, and which are still implied?
Final take
By Post 13, the series has arrived at its main architectural answer.
A production-shaped agent harness is not defined by whether it has tools, memory, or multiple roles. It is defined by whether those capabilities sit inside a runtime with explicit contracts:
- typed tools
- policy boundaries
- approval gates
- durable state
- traceable execution
- inspectable memory layers
- honest limitations
The new blueprint export in 67ailab/harness-engineering matters because it turns that answer into a real artifact. You can run it. You can read it. You can compare it to the code. And you can see, in one place, that the model is only one component in a larger engineered system.
That is harness engineering.
References
67ailab/harness-engineering- Temporal Workflow Execution overview
- Model Context Protocol Specification
- OpenAI Latency Optimization Guide
-
Temporal’s workflow execution docs are useful here because they frame durability, replay, and resumability as runtime properties rather than as ad hoc application behavior. ↩︎
-
The MCP specification is useful both for its tool/resource model and for its explicit security and consent guidance around tool invocation. ↩︎ ↩︎
-
The OpenAI latency guide is framed as performance advice, but for agent systems it is really a reminder that orchestration shape determines latency as much as model choice does. ↩︎