The live demo repo for this series is 67ailab/harness-engineering. This first post is grounded in the current public repo state rather than a made-up architecture diagram. For this article, I did not add a new repo feature before publishing; the existing baseline already supports the core claim. At the time of writing, that baseline includes typed tools, checkpointed run state, resumable execution, an approval gate before writing artifacts, per-step traces, a planner/reviewer split, and optional local OpenAI-compatible model support.
That is the thesis in one sentence: the thing that makes an agent usable in the real world is usually not the prompt. It is the harness.
Prompt engineering still matters. A bad instruction set can absolutely ruin output quality. But when teams move from toy demos to systems that touch files, APIs, humans, or money, the first serious failures usually come from somewhere else:
- the model called the wrong tool because the contract was vague
- a flaky dependency failed once and the run died permanently
- a risky action executed without a real approval boundary
- the process crashed and there was no restart point
- nobody could explain what the agent actually did
- a human said “wait” but the runtime had no concept of “paused pending approval”
Those are harness failures.
The demo makes the point better than the slogan
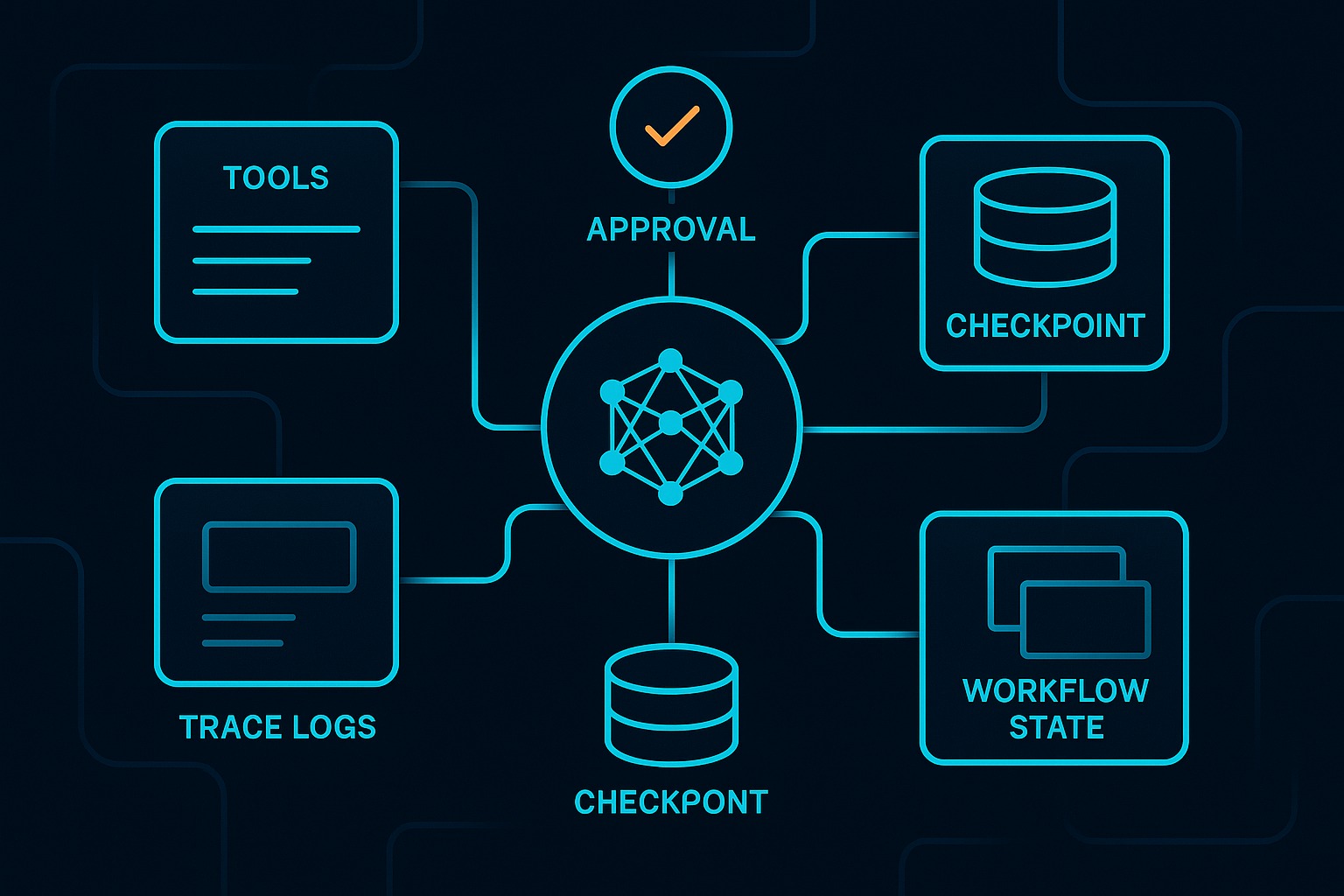
The repo’s structure is intentionally small enough to read in one sitting. The important files are all under src/harness_engineering/:
tools.pydefines the tool contract boundaryrunner.pydefines the workflow loop and approval behaviormodels.pydefines persistent run state, step results, and trace eventsstore.pypersists state and traces under.runs/<run_id>/cli.pyexposes start, inspect, approve, resume, interactive, and doctor commandsreviewer.pyandprovider.pyshow how model-backed planning/review can exist without becoming the whole system
That division is the article’s argument in code form. The model is present, but it is not the architecture.
If you open src/harness_engineering/tools.py, the center of gravity is not “prompt magic.” It is a small typed registry:
ToolToolRegistrydefault_registry()
Each tool has a name, description, input_schema, risky flag, and handler. Even in this tiny repo, that matters. finalize_report is marked risky because it writes to disk. search_mock, extract_facts, and draft_report are not. That sounds obvious, but this is exactly the kind of distinction many agent demos skip. They let the model produce prose about an action and then quietly execute it in application code with no explicit policy boundary.
This repo does the opposite. It names the boundary.
The runtime, not the prompt, owns reliability
Look at HarnessRunner in src/harness_engineering/runner.py. The key methods are:
create_run()_execute()run_until_pause_or_complete()approve()resume()
This is where the real engineering lives.
create_run() initializes a RunState, records the plan, saves the planner identity, and emits a run_created trace event. Already that is more production-minded than most one-shot agent demos. A run becomes an object with identity and state, not just a transient model response.
_execute() wraps every tool invocation with tracing and retry behavior. It emits tool_start, captures success or failure in a StepResult, emits tool_ok or tool_error, and persists the updated state. The retry behavior itself is currently simple—RetryPolicy(max_attempts=2)—but the important part is architectural: retry logic lives in the harness instead of being hand-waved away.
Then run_until_pause_or_complete() makes the central design choice explicit. The workflow progresses from search_mock to extract_facts to draft_report, but when it reaches finalize_report, the harness does not treat approval as a chat convention. It treats approval as workflow state:
state.requires_approval = Truestate.pending_action = "finalize_report"state.status = "waiting_approval"
That is the difference between a demo and a system.
If a human needs to approve a risky action, the system should not depend on someone remembering a polite instruction in chat history. It should expose a durable, inspectable state transition. In this repo, approval is not prose. It is part of the state machine.
A real run shows why this matters
I verified the repo before writing this post with:
make checkPYTHONPATH=src python3 -m harness_engineering.cli doctor
The checks passed. The repo’s tests cover pause/resume, retry, store round-trips, interactive approval, and mock planning/review in tests/test_harness.py. The doctor command also succeeded against the repo-local OpenAI-compatible configuration, confirming that the configured local model endpoint was reachable and that the selected model was available.
I then ran the demo and inspected the resulting artifacts under .runs/.
In one verified run, the stored state.json showed:
status: "running"whiledraft_reportwas executing- planner recorded as
openai_compatible - extracted matches and facts stored as artifacts
- a persistent trace log with
run_created,tool_start, andtool_okevents
That trace existed because src/harness_engineering/tracing.py appends TraceEvent objects via add_trace(), and src/harness_engineering/store.py writes both state.json and trace.json on save. Again, none of that is prompt engineering. It is harness engineering.
Without this layer, a team can get a decent paragraph from a model but still have no answer to basic operational questions:
- What step was the agent on when it stopped?
- Was the last tool call successful?
- What arguments were used?
- Is the run resumable?
- Was approval granted or not?
- Did the report draft come from the mock provider or the configured local model?
The demo answers those questions because its runtime was designed to answer them.
Why prompt engineering is the wrong place to put too much faith
The current repo does contain prompts. src/harness_engineering/provider.py uses prompts in build_report_markdown(). src/harness_engineering/reviewer.py uses prompts in build_plan() and review_markdown() when an OpenAI-compatible client is configured. That is fine. A harness without prompts would be silly.
But the important thing is what those prompts are allowed to do.
They do not get to decide whether disk writes are safe. They do not get to define persistence semantics. They do not decide how retries work. They do not define the authoritative run status. They do not decide where artifacts are written.
The harness decides those things.
That separation is what keeps an agent system legible. A model can help write a plan or improve a draft. It should not silently become the owner of operational guarantees.
This is also where a lot of current AI discourse gets confused. Tool calling makes the model feel agentic, so people assume the hard problem is “teach the model to use tools well.” That is only part of it. OpenAI’s tool-calling documentation describes the familiar loop: send tools to the model, receive a tool call, execute it application-side, pass tool output back, then receive a final response. Anthropic’s Messages API similarly structures inputs as explicit messages and content blocks. And the Model Context Protocol standardizes how hosts, clients, and servers expose resources, prompts, and tools over JSON-RPC.
All of that is useful. None of it, by itself, gives you durability, approval policy, artifact persistence, or resumable execution.
MCP is especially worth being precise about. The specification is clear that tools create real trust-and-safety issues and that users should explicitly authorize operations. That is exactly why MCP should be treated as a connectivity and interoperability layer, not as a substitute for harness design. Standardized tool access helps. It does not remove the need for workflow state, policy, and audit trails.
What the demo proves
This repo is small, but it proves a few important things cleanly.
1. Approval should be a workflow primitive
The strongest design choice in the repo is the transition into waiting_approval before finalize_report. The CLI surface in src/harness_engineering/cli.py reinforces that boundary through cmd_approve() and cmd_resume(), and the interactive mode makes it visible to a human operator.
That proves a practical point: human-in-the-loop does not need to mean “someone typed yes in Slack.” It can mean the runtime exposes a first-class pending action with explicit state and a deterministic resume path.
2. Tool contracts are application code, not model vibes
In tools.py, the tool registry is explicit enough that another engineer can inspect what the agent may do without reverse-engineering a prompt. That improves reviewability, testing, and policy discussion. If you want to mark a tool as risky, you can do it in code.
3. Persistence changes the shape of the system
RunState in models.py contains status, current_step, requires_approval, pending_action, artifacts, trace, and step_results. That means the system can stop being a single request-response interaction and become a long-lived run with memory of what already happened.
That is the first step toward durable agents. Not distributed durability, not industrial orchestration yet, but the right shape.
4. Model optionality is healthier than model centrality
The repo can run with no external model at all, because create_client_from_env() in provider.py falls back to mock behavior when no OpenAI-compatible configuration is active. When configured, doctor_check() verifies connectivity and model availability. That is a good harness instinct: make the model pluggable, observable, and testable instead of mystical.
5. Traces are part of the product
The trace events in .runs/<run_id>/trace.json are not a luxury. They are the beginnings of operational truth. When an agent system surprises you, traces are how you recover the causal chain.
What it still does not solve
It is just as important to be honest about what this repo does not prove.
1. It is not a full policy engine
The risky/non-risky distinction is useful, but still minimal. There is no general authorization framework, no role-based access control, and no separate sandbox enforcing tool isolation. A mature harness would need stronger policy configuration and runtime enforcement.
2. It is not durable across machines or workers
Persistence under .runs/ is great for local reproducibility and demos. It is not the same as distributed durable execution. There is no external database, queue, lease management, or worker recovery across hosts.
3. The tool layer is still intentionally simple
search_mock() is lexical matching over a local JSON file. extract_facts() is simple sentence slicing. That is fine for clarity, but it is not a realistic research pipeline. The point here is harness shape, not search quality.
4. Retry is present but shallow
A fixed retry wrapper is better than none, but real systems need richer backoff, retry classification, budgets, idempotency handling, and better visibility into downstream failure modes.
5. Observability is local, not platform-grade
JSON traces on disk are enough to make the architecture legible. They are not a substitute for production observability: no dashboards, no span correlation, no metrics backend, no SLOs, no distributed tracing integration.
6. The planner/reviewer split is modest, not theatrical
The repo now has planner and reviewer roles, but this is still a disciplined single-run harness, not a sprawling multi-agent society. That is a good thing. It keeps the real question visible: does the role split improve control and verification, or is it just adding ceremony?
Honest limitation: the model is not where the deepest reliability work is happening
That is not an insult to models. It is just an engineering observation.
In this repo, the model may help produce a cleaner plan or a better draft report when OpenAICompatibleClient is available. But if you remove the harness and keep only the prompt, you lose the properties that matter most for operating an agent system with real side effects.
You lose:
- explicit state transitions
- durable run identity
- resumability
- traceability
- inspectability
- a visible approval boundary
- a structured place to insert policy
And once those are gone, it barely matters how elegant the prompt was.
What changed in the repo for this post
Because this is the first post in the series, there is no previous harness post to diff against. For this run, no new repo capability was required before publication. The article is based on the current public baseline: the approval-gated research harness, the local-model doctor flow, the planner/reviewer split, and the interactive CLI path already present in the repo.
That is actually fitting. The first post should establish the thesis before the series adds more machinery.
The real takeaway
If you are building agent systems, it is fine to care about prompts. You should care about prompts. But if your system can call tools, write files, wait for humans, resume after interruption, or produce outputs that anyone will rely on, the harder and more important work is around the model.
That work looks a lot like ordinary systems engineering:
- state machines
- typed interfaces
- retries
- persistence
- approvals
- traces
- policy boundaries
- test coverage
In other words: harness engineering.
That is why this topic matters more than prompt engineering in production settings. Prompts influence behavior. Harnesses determine whether that behavior is governable.
And governability is what turns an impressive demo into software you can actually trust.
In the next post, I’ll break down the repo more mechanically and map the demo into its core parts: runner, tools, store, CLI, and state model. The first article is the thesis. The second will be the anatomy.
References
- 67 AI Lab,
harness-engineeringrepository: https://github.com/67ailab/harness-engineering - OpenAI, “Function calling”: https://developers.openai.com/api/docs/guides/function-calling
- OpenAI, “Using tools”: https://developers.openai.com/api/docs/guides/tools
- Anthropic, “Messages API”: https://docs.anthropic.com/en/api/messages
- Model Context Protocol Specification (2025-06-18): https://modelcontextprotocol.io/specification/2025-06-18