The live demo repo for this series is 67ailab/harness-engineering, and for this post I did change the repo before publishing. The new capability shipped in commit 98c6302, which adds an explicit policy layer to the harness: tools now carry action categories, risky writes are checked against allowed output roots before execution, and policy decisions are persisted in traces and summaries.
The key code changes are in:
src/harness_engineering/policy.pysrc/harness_engineering/tools.pysrc/harness_engineering/runner.pysrc/harness_engineering/cli.pysrc/harness_engineering/mcp.pysrc/harness_engineering/tracing.pysrc/harness_engineering/store.pysrc/harness_engineering/workflow.pysample_data/policy/restrictive.json
That matters because “sandboxing” gets used too loosely in agent conversations. Sometimes people mean a real OS sandbox. Sometimes they mean a container. Sometimes they mean “the model only has a few tools.” Those are not the same thing.
My claim in this post is narrower and more practical: before you can talk seriously about agent isolation, you need explicit runtime boundaries in the harness itself. If the harness cannot classify actions, gate risky side effects, record denials, and preserve those rules across pause/resume, then the rest of your safety story is hand-waving.
This repo still does not implement OS-level isolation. It does now implement a real harness-level policy boundary. That is worth showing clearly because it is the layer many demos skip.
What changed in the repo since the previous post
Post 8 added better observability through build_trace_summary(state) in src/harness_engineering/tracing.py and a lightweight eval runner in src/harness_engineering/evals.py. That made the runtime more legible.
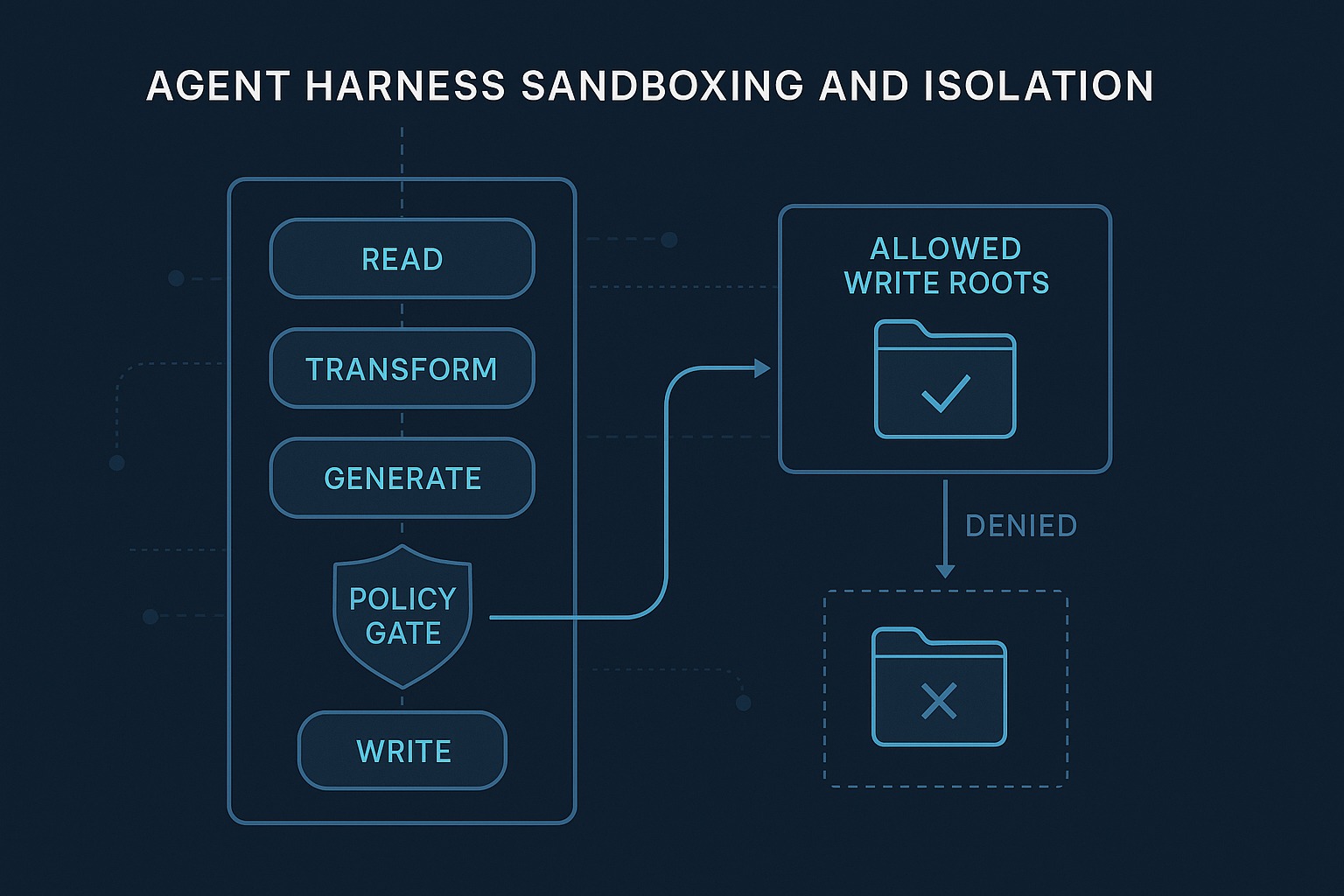
For Post 9, the repo needed a stronger answer to a basic question: what stops a tool from performing a risky side effect in the wrong place?
Previously, the demo mostly treated safety as a boolean property of a tool. finalize_report was marked risky, and the run paused for approval before writing the final markdown file. That was already useful. But it was not enough to support a serious post about isolation.
The missing pieces were:
- a way to classify tool actions beyond
risky=True - an explicit policy object that could evaluate proposed actions
- enforcement of allowed write destinations
- persisted policy decisions in run artifacts and traces
- a CLI surface to inspect the active policy
- correct policy reloading on
approveandresume
Those are now present.
The new policy surface in the live repo
The center of the change is PolicyEngine in src/harness_engineering/policy.py.
That module introduces:
DEFAULT_ACTION_CATEGORIESPolicyDecisionPolicyEnginedefault_policy_config()load_policy_file()
The important design choice is that the policy system is not a separate abstract document first. It is derived from the live tool registry and then optionally overridden by a JSON file.
In src/harness_engineering/tools.py, the Tool dataclass now includes:
action_category: str = "utility"
The default registry assigns concrete categories:
search_mock→read_onlyextract_facts→transformdraft_report→model_generationfinalize_report→filesystem_writeflaky_echo→utility
That is a small taxonomy, but it is already much more useful than “safe tool” versus “unsafe tool.” It lets the harness talk explicitly about the kind of action being attempted.
Then default_policy_config() builds a policy from the live registry. For filesystem_write tools, it automatically constrains writes to the current runs directory. In other words, the default policy is not “writes are risky but probably fine.” It is “writes are risky, require approval, and must stay inside the harness-owned output root.”
That is the first concrete isolation boundary in this repo.
Where enforcement actually happens
The most important implementation detail is in HarnessRunner._execute() inside src/harness_engineering/runner.py.
Before a tool runs, the runner now does this conceptually:
- look up the tool
- call
self.policy.evaluate(tool_name, kwargs) - record the resulting
PolicyDecision - emit a
policy_checkedtrace event - deny execution immediately if the action is not allowed
- otherwise continue to
tool_startand actual tool execution
That means policy is not merely metadata. It is in the execution path.
When policy denies an action, _execute():
- appends a failed
StepResult - marks the run
failed - clears
pending_action - emits
policy_denied - persists the updated state
That is exactly what I want from a harness policy boundary. A denial should be explicit, durable, inspectable, and boring.
There is also a second, very deliberate enforcement point in the draft_report branch of run_until_pause_or_complete(). Before the harness even pauses for approval, it computes the future output path for finalize_report and asks policy whether that write would be allowed.
So the repo now distinguishes two ideas that often get blurred together:
- approval: a human must authorize the risky action
- policy: the action must be structurally allowed at all
If policy says the write target is outside the allowed roots, the run fails before approval. That is correct. Human approval should not be a magic override for a disallowed target unless you explicitly design it that way.
Real examples from the live repo
Before writing this post, I verified the repo state in /home/james/.openclaw/workspace/harness-engineering.
I ran the required checks:
make check
PYTHONPATH=src python3 -m harness_engineering.cli doctor
Those passed.
make checkcompleted successfully, including the secret scan.doctorreturnedstatus: okagainst the repo’s configured local OpenAI-compatible endpoint using modelgemma4athttp://192.168.0.16:8080/v1.
I then exercised the live policy logic in two concrete ways using the repo code.
Example 1: allowed write under the harness run root
Using the live HarnessRunner, default registry, and default PolicyEngine, I created a run that paused for approval and then completed successfully.
That run was:
- run ID:
394c54fa-12e1-4516-8ee6-43cedb3cccd6 - initial status after start:
waiting_approval - final status after approve/resume:
completed
The saved pending action included:
action:finalize_reportaction_category:filesystem_writeproposed_output_path:/home/james/.openclaw/workspace/harness-engineering/.runs-article-success/394c54fa-12e1-4516-8ee6-43cedb3cccd6/final_report.md
The resulting trace summary showed:
policy.checks: 5policy.denials: 0- latest decision for
finalize_reportwithallowed: true - reason:
Write targets are allowed under: /home/james/.openclaw/workspace/harness-engineering/.runs-article-success. - action-category counts including
filesystem_write: 4 - approval events present
run_completedpresent
That is the happy path the post needs to describe honestly. The write is risky, it is approval-gated, and it is also path-constrained.
Example 2: denied write outside allowed roots
The repo also includes a restrictive sample policy at sample_data/policy/restrictive.json:
{
"version": 1,
"default_allowed_write_roots": ["/tmp/definitely-not-the-harness-runs-dir"],
"tool_policies": {
"finalize_report": {
"enabled": true,
"action_category": "filesystem_write",
"allowed_output_roots": ["/tmp/definitely-not-the-harness-runs-dir"]
}
}
}
Using that policy with the live runner, I got a real denial:
- run ID:
197ecaec-37eb-4efc-bffe-1d70f48095da - final status:
failed - pending action:
None
The latest persisted PolicyDecision for finalize_report was:
allowed: falseaction_category: filesystem_write- reason: the write target under
.runs-article-denied/.../final_report.mdwas outside the allowed root/tmp/definitely-not-the-harness-runs-dir
The trace summary for that run reported:
policy.checks: 4policy.denials: 1- latest event:
policy_denied - no final report path
That is the more important example, frankly. It proves the repo is not just decorating tools with labels. It is actually refusing an out-of-policy side effect.
Why this matters for “sandboxing” discussions
The MCP specification is quite explicit that tool use introduces real security and trust concerns, that tool descriptions should be treated cautiously, and that hosts should provide clear authorization flows and user control. But MCP is a protocol surface, not a full runtime safety system. It standardizes how capabilities are exposed; it does not by itself enforce durable approvals, write boundaries, or resumable policy state.
That is exactly the gap this repo is trying to illustrate.
Similarly, frameworks like LangGraph emphasize durable execution, human-in-the-loop control, and persistence, while workflow systems like Temporal frame durable execution around explicit state progression and replay. Those ecosystems are much broader than this demo, but they point in the same direction: reliable systems depend on runtime boundaries and durable control state, not just on convenient tool APIs.
In this repo, the policy layer is still small. Good. It still demonstrates three important engineering habits:
- classify actions explicitly
- evaluate policy before execution
- persist the decision as part of run history
That is already more useful than vague claims about “safe agents.”
The CLI and inspection surfaces matter too
A policy boundary is much more credible when operators can inspect it directly.
The repo now adds cmd_policy() in src/harness_engineering/cli.py, exposed as:
PYTHONPATH=src python3 -m harness_engineering.cli policy --pretty
That prints the effective policy, including:
- policy version
- active policy file if one is used
- store root
- default allowed write roots
- tool policies with action categories
This is complemented by two other surfaces.
First, tool_to_mcp_descriptor() in src/harness_engineering/mcp.py now exports meta.actionCategory alongside meta.risky. That means the harness’s internal safety vocabulary also appears in the MCP-style tool descriptor surface.
Second, build_trace_summary(state) in src/harness_engineering/tracing.py now reports policy counts and the latest policy decision. RunStore.save() in src/harness_engineering/store.py persists those summaries to trace_summary.json on every save.
That combination matters. Policy is no longer hidden inside runner logic. It is visible in descriptors, traces, summaries, and CLI output.
A subtle bug this repo change had to fix
One of the more interesting real bugs here was not about denial logic. It was about durability.
When I first added custom policy loading, start could create a run with a policy file, but approve and resume rebuilt the runner with defaults. That meant a run could begin under one policy and resume under another. For a post about isolation, that would have been unacceptable.
The fix is in src/harness_engineering/cli.py:
_build_runner()constructs a runner from a runs directory plus either a policy file or saved policy config_build_runner_for_existing_run()reloads the saved run state and reconstructs the runner using the policy stored instate.artifacts["policy"]
Then cmd_approve() and cmd_resume() use _build_runner_for_existing_run().
This is exactly the kind of bug harness engineers should care about. Safety rules are part of execution state. If they are not preserved across resume, they are not real runtime constraints.
What the demo proves
1. Harness-level policy is a meaningful isolation layer
This repo still runs on the local machine and writes local files. But it now proves that a harness can impose explicit action categories and hard path constraints before side effects happen.
2. Approval and policy are different controls
The new flow shows that a risky action can require human approval and still be denied by policy. Those are separate mechanisms and should stay separate.
3. Policy decisions should be durable artifacts
The repo records policy decisions in state.artifacts["policy_decisions"], emits policy_checked and policy_denied trace events, and includes policy data in compact trace summaries. That is the right pattern for auditability.
4. Resume correctness is part of the safety story
The _build_runner_for_existing_run() fix proves an important operational point: if policy is configurable, the harness must reload the same effective policy when continuing a run.
What it still does not solve
This section matters more than the happy path.
1. This is not an OS sandbox
The repo does not provide container isolation, seccomp, namespace isolation, subprocess jails, VM boundaries, or network egress controls. If you need those, you need lower-level system controls in addition to harness policy.
2. The policy model is still narrow
Today the meaningful hard check is write-path enforcement for filesystem_write. There is no first-class policy for network destinations, subprocess execution, credential scope, per-user permissions, or time/resource quotas.
3. Action categories are hand-authored
The taxonomy is explicit, which is good, but still small and manually assigned. Real systems often need richer capability modeling and stronger review around tool registration.
4. The local-model reviewer path still has a known weakness
During verification, the repo-local OpenAI-compatible model connectivity was healthy, but a live local-model run still exposed the current reviewer fragility around structured JSON output. That is an honest limitation of the demo. For the policy examples above, I used the live repo code with deterministic mock behavior to get reproducible approval and denial traces.
5. There is no secret or credential isolation per tool
The harness can say where a file may be written. It cannot yet say which credential a tool may use, or prevent a broadly privileged tool from seeing too much ambient authority.
Practical takeaway
When people say “safe agent execution,” I think the useful first question is not “which model?” It is:
- what are the action categories?
- where are the risky boundaries?
- what is structurally forbidden?
- where are denials recorded?
- do those rules survive pause and resume?
This repo now has a concrete answer for one important class of side effect: filesystem writes.
That is not the end state. It is the start of a real one.
A lot of agent demos jump directly from tool calling to grand claims about autonomy. I trust systems more when they first show me something simpler and stricter:
- classify the action
- check the rule
- deny the bad path
- persist the evidence
That is not glamorous. It is harness engineering.
References
- 67 AI Lab,
harness-engineeringrepository: https://github.com/67ailab/harness-engineering - Model Context Protocol specification (2025-03-26): https://modelcontextprotocol.io/specification/2025-03-26
- LangGraph overview: https://docs.langchain.com/oss/python/langgraph/overview
- OpenAI Agents SDK documentation: https://openai.github.io/openai-agents-python/
- OpenTelemetry documentation, “Traces”: https://opentelemetry.io/docs/concepts/signals/traces/
- Temporal documentation, “Workflow Execution”: https://docs.temporal.io/workflow-execution