The live demo repo for this series is 67ailab/harness-engineering. For this final post, I did not change the repo before publishing; the codebase discussed here is the current public state at commit 7d01dae, the same commit introduced in the previous post when the repo gained a real blueprint export. That matters because this article is not about an imaginary next step. It is about what the current repo already makes obvious once you stop looking at MCP as the finish line.
MCP has been one of the healthiest developments in the agent ecosystem. It gives hosts, clients, and servers a shared way to talk about tools, resources, prompts, and related capabilities over JSON-RPC. That is useful. It reduces adapter churn. It makes tool surfaces less bespoke. It helps separate a model-facing interface from internal implementation details.
But production agent systems do not fail because the tool descriptor shape was slightly inconsistent.
They fail because nothing reliable happens after the tool descriptor.
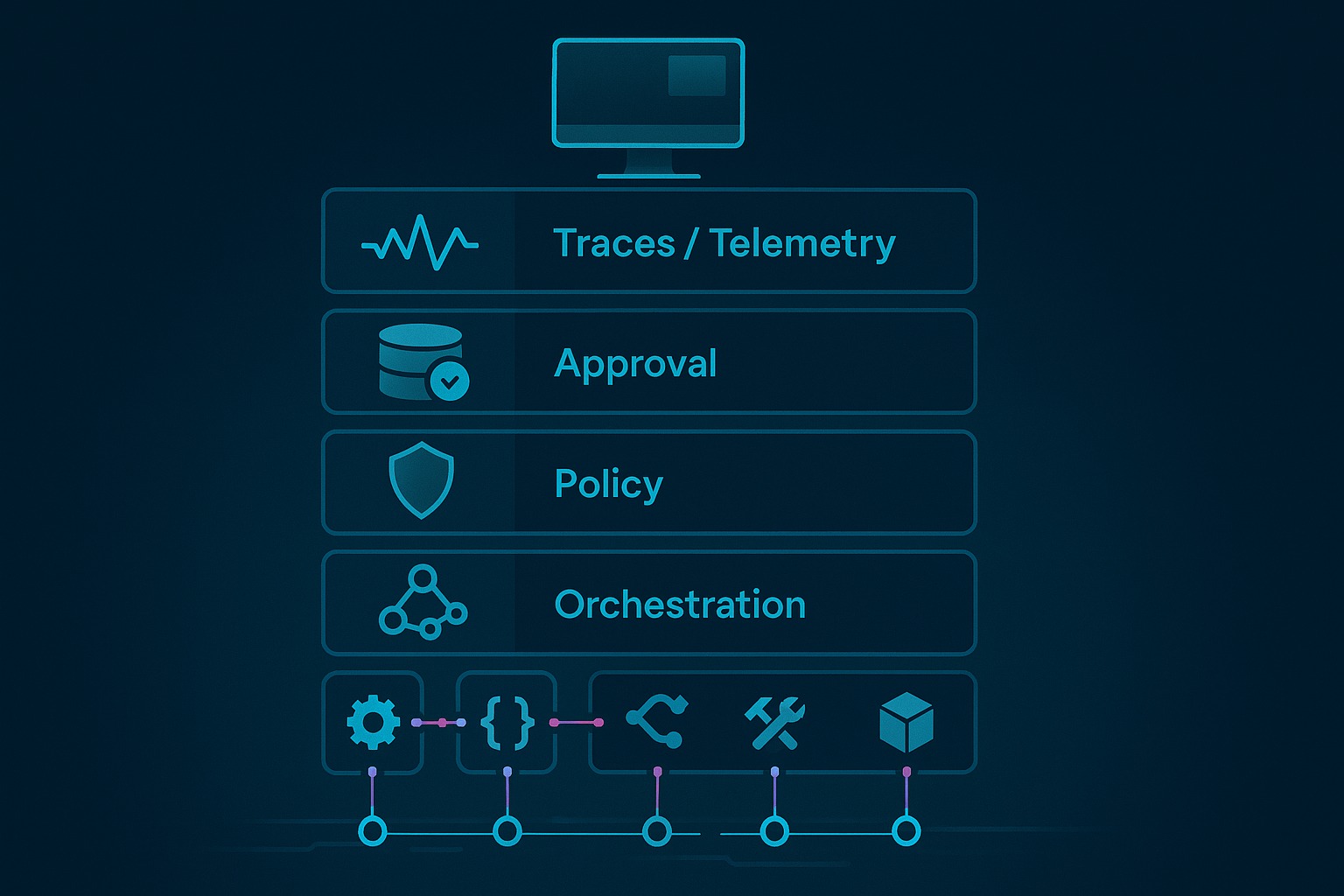
That is the argument of this whole series, and the final state of the demo repo is a good place to land it. Once you inspect the current code, the practical answer to “what comes after MCP?” is not a mysterious new protocol. It is a stack of runtime responsibilities that sit above and around protocol compatibility:
- orchestration
- policy
- approval
- durable execution
- observability
- memory separation
- role boundaries
- operator-facing artifacts
MCP is a protocol layer. An agent harness is a runtime.
That distinction is where most of the real engineering work starts.
What changed in the repo since the previous post
Nothing in the repo changed for this post. That is deliberate.
Post 13 added the blueprint export in src/harness_engineering/blueprint.py and exposed it through cmd_blueprint() in src/harness_engineering/cli.py. That means this final essay can use the repo’s own architecture artifact instead of inventing a fresh diagram for narrative convenience.
You can inspect the current demo with:
PYTHONPATH=src python3 -m harness_engineering.cli blueprint --pretty
PYTHONPATH=src python3 -m harness_engineering.cli workflow --pretty
PYTHONPATH=src python3 -m harness_engineering.cli policy --pretty
PYTHONPATH=src python3 -m harness_engineering.cli mcp-tools --pretty
And, if you are using the repo-local OpenAI-compatible configuration, the provider path can be verified with:
PYTHONPATH=src python3 -m harness_engineering.cli doctor
On the machine used for this post, that doctor check returned status: "ok" and message: "MODEL_OK" for the repo’s configured local openai_compatible provider. So when I refer to the provider layer below, I am referring to a real verified path in the demo, not a placeholder.
MCP solves interface standardization, not runtime design
The repo’s MCP surface lives in src/harness_engineering/mcp.py, and the important functions are easy to name:
tool_to_mcp_descriptor()registry_to_mcp_tools()validate_tool_arguments()call_tool_mcp()
That file does exactly what a sane protocol adapter should do. It converts internal tools into MCP-shaped descriptors, validates arguments against the registry’s declared schema, and returns MCP-shaped call results with both content and structuredContent.
That is good engineering. It is also not remotely enough.
The Model Context Protocol specification is explicit about its scope: it standardizes how applications share context, expose tools, and negotiate capabilities between hosts, clients, and servers. It also explicitly emphasizes user consent and caution around tool execution. That last part is especially important. A protocol can define how a tool is described and called; it cannot guarantee that the host application has built a decent approval path, a durable runtime, or a policy model worth trusting.
The repo makes this concrete. In src/harness_engineering/tools.py, a tool is not just a name and handler. The Tool dataclass includes:
namedescriptioninput_schemariskyhandleraction_category
That extra action_category field is where the harness starts becoming more than a protocol adapter. draft_report is categorized as model_generation. search_mock is read_only. finalize_report is filesystem_write and explicitly marked risky.
If all you had was MCP compatibility, you would know how to describe finalize_report to a model. You would not yet have decided whether the model should be allowed to execute it, where it can write, whether it needs human approval, how that decision is persisted, or how an operator inspects the pending action later.
That is what comes after MCP.
After protocol compatibility, you need orchestration
The center of the repo is still HarnessRunner in src/harness_engineering/runner.py.
The functions that matter most are:
create_run()run_until_pause_or_complete()_execute()_estimate_step_metrics()approve()resume()
If I had to summarize the repo in one sentence, it would be this: the harness is the control loop that turns model/tool capability into a governed workflow.
call_tool_mcp() can tell you whether a tool call structurally succeeded. HarnessRunner.run_until_pause_or_complete() decides what the system actually does next.
That difference is the entire game.
The current workflow is intentionally modest. build_workflow_definition() in src/harness_engineering/workflow.py exports a linear state machine:
initsearch_mockextract_factsdraft_reportwaiting_approvalfinalize_reportdonefailed
That is not flashy. It is better than flashy.
The exported transition model shows where success moves forward, where failure terminates, and where approval gates interrupt execution. workflow_to_mermaid() can render the same shape as a diagram, but the interesting part is not the Mermaid string. The interesting part is that the graph is exported from the runtime’s real logic, not written as separate architecture theater.
This is one of the main lessons I would carry forward from the project: once tool calling is standardized, the next differentiator is orchestration clarity. Can you name the states? Can you export the transitions? Can you explain exactly why the run is paused, failed, or resumable?
If not, protocol compatibility is mostly cosmetic.
After orchestration, you need durable execution
The strongest “what comes after MCP” answer in this repo is RunStore in src/harness_engineering/store.py.
RunStore.save() persists a run into a directory of explicit artifacts:
state.jsontrace.jsonsummary.jsonmemory.jsontrace_summary.jsonhandoffs.json- and, when approved,
final_report.md
That list should matter more to infrastructure engineers than yet another tool schema screenshot.
Why? Because protocol compatibility helps a model ask for work. Durable execution helps a system survive real work.
Temporal’s workflow documentation is useful here as a reference point. It describes workflow execution as durable, reliable, and resumable, with replay driven by persisted event history. This demo is much smaller than Temporal and does not claim deterministic replay. But it points in the same direction architecturally: once you treat agent execution as a series of persisted state transitions rather than as a long prompt with side effects, the whole design changes.
In this repo, durability shows up in practical operator surfaces:
RunStore.build_summary()rolls up status, attempts, approval state, performance, and next commands.RunStore.history()exposes replay-friendly trace inspection.HarnessRunner.resume()loads the run and continues from persisted state.- the CLI maps those surfaces to
summary,history,inspect,pending,approve, andresumecommands.
That is what I mean by the next layer. After MCP, you need a system that can pause at 3:00 PM, survive a crash at 3:01 PM, and still give an operator coherent artifacts at 3:02 PM.
A lot of agent stacks still have nice protocol stories and terrible runtime stories.
After durability, you need policy and approval as workflow primitives
The most important non-protocol file in the repo may be src/harness_engineering/policy.py.
The relevant pieces are:
PolicyDecisionPolicyEngine.describe()PolicyEngine.evaluate()default_policy_config()load_policy_file()
PolicyEngine.evaluate() does not ask whether a tool call is valid JSON. It asks whether the action should be allowed.
That is a qualitatively different question.
The default policy model is intentionally small, but the shape is correct. Tools can be enabled or disabled by name. Action categories are explicit. Filesystem writes are constrained to allowed roots. Relative policy paths are resolved from the policy file’s location. finalize_report is allowed to write only under the repo’s .runs directory.
Then HarnessRunner._execute() records the policy decision, emits a policy_checked trace event, denies the step if needed, and persists the result. For finalize_report, run_until_pause_or_complete() goes further: it evaluates policy before the write, constructs pending_action_details, marks the run as waiting_approval, and persists a structured approval payload before the risky action can happen.
This is the practical answer to the MCP spec’s safety language about explicit user consent around tools. Consent is not a sentence the model prints. Consent is a runtime boundary.
I think that is one of the most underappreciated design principles in agent systems.
Bad version:
- the model says “shall I continue?”
- the user says “yes”
- the system hopes that string matching counts as approval
Better version:
- the runtime sets
requires_approval - the pending action is explicit
- the proposed output path is recorded
- a preview is stored
- the operator has inspect/approve/resume commands
- the trace records
approval_requiredandapproval_granted
Once you have that, you are building a system instead of roleplaying one.
After policy, you need observability that operators can use
Another thing that comes after MCP is trace discipline.
The repo’s tracing layer is tiny and effective:
add_trace()insrc/harness_engineering/tracing.pybuild_trace_summary()in the same file
Every meaningful transition ends up in trace data. Tool starts. Tool success. Tool failure. Policy checks. Policy denials. Approval events. Role activity. Handoffs. Run completion.
Then build_trace_summary() rolls those raw events up into something an operator can actually read:
- counts by event
- counts by tool
- attempts by tool
- counts by action category
- duration by tool
- estimated token/workload summaries for model steps
- approval status
- policy checks and denials
- multi-agent handoff counts
- final artifact presence
That summary is a strong example of the layer after protocol standardization. MCP can tell you how a tool is exposed. It does not tell you how to answer these questions after a bad day in production:
- Which tool is slow?
- Which step retried?
- Which risky action was blocked by policy?
- Which role performed the last review?
- Did the run pause because approval was missing or because the reviewer failed?
You need traces, summaries, and persisted history for that.
OpenAI’s latency optimization guidance also fits naturally here. The useful lesson is not merely “pick a faster model.” It is that overall latency is shaped by request count, token volume, parallelization choices, and whether you are using an LLM where ordinary code would do. Those are harness-level decisions. They belong to runtime design, not protocol compliance.
After observability, you need memory separation and role boundaries
One of the quieter but better parts of the repo is src/harness_engineering/memory.py.
It exports:
build_working_context()build_session_state()retrieve_memory()build_memory_snapshot()
This is a small codebase, but it makes a crucial architectural distinction: working context, session state, and retrieval memory are not the same thing.
That separation matters more after MCP than before it. Once tools are standardized, the next failure mode is context inflation and state confusion. Teams throw chat history, retrieved documents, plan state, approval state, and operator notes into one giant blob and call it “memory.” That works right up until nobody can tell what should persist, what should be recomputed, and what the model actually needs for the next step.
The repo avoids that trap. Memory is a snapshot artifact, not a mystical subsystem.
The same honesty shows up in src/harness_engineering/multi_agent.py, especially:
planner_step()reviewer_handoffs()build_multi_agent_snapshot()
The repo’s multi-agent mode does not pretend to be a swarm. It keeps the same small workflow and records explicit planner, executor, and reviewer activity plus persisted handoffs. That is the right lesson to end the series on. After MCP, the next layer is not “more agents.” It is sharper contracts between roles, plus artifacts that let you audit those handoffs later.
The provider layer is part of the harness too
One final thing that often gets left out of MCP-heavy conversations: provider handling is also part of what comes after the protocol.
In this repo, src/harness_engineering/provider.py includes:
load_dotenv()load_model_config()create_client_from_env()build_report_markdown()doctor_check()
That is not glamorous, but it is real infrastructure. The harness supports a mock path and an OpenAI-compatible path. It prefers repo-local HARNESS_* variables when configured. It can validate /models and a minimal chat round trip before you rely on local model behavior.
That is the kind of practical edge work people skip when they talk about agent architecture only at the protocol level. A system is not ready because its tools are standardized. It is ready when an operator can verify that the configured provider exists, the selected model is reachable, and the runtime can fall back or fail clearly.
What the demo proves
First, it proves that MCP is valuable but incomplete. Standardized tool descriptors are a clean interface boundary, not a substitute for orchestration.
Second, it proves that the important post-MCP layers can be implemented concretely in a small repo and named precisely in code:
- orchestration in
HarnessRunnerandbuild_workflow_definition() - durable artifacts in
RunStore.save()andRunStore.build_summary() - policy in
PolicyEngine.evaluate() - approval in
run_until_pause_or_complete()and the persistedpending_action_details - observability in
add_trace()andbuild_trace_summary() - memory separation in
build_memory_snapshot() - provider verification in
doctor_check() - architecture export in
build_reference_blueprint()andcmd_blueprint()
Third, it proves that “what comes after MCP” is not a single silver-bullet protocol or framework. It is a control plane made of explicit runtime contracts.
Fourth, it proves that honest limits make a better demo. This repo keeps the workflow small, the policy local, and the multi-agent story restrained. That makes the engineering argument stronger, not weaker.
What it still does not solve
This demo is still a local Python harness.
It does not provide:
- a distributed workflow runtime
- deterministic replay semantics in the Temporal sense
- queue-backed workers
- OS-level sandboxing or network egress isolation
- identity-aware authorization
- provider-accurate billing integration
- large-scale concurrency control
- formal persisted-schema migration management
- a real networked MCP server transport
It also does not magically solve the organizational problems around agent systems: deciding who owns policies, how approval burdens are distributed, how eval regressions block deployment, or when classical software should replace a model step entirely.
Those gaps matter. They are exactly why I do not buy the idea that protocol standardization alone will make agent systems production-ready.
Final take
The whole series started from a simple claim: prompt engineering is not the main reliability frontier. Harness engineering is.
At the end of the series, I would sharpen that claim a bit further.
MCP is the start of agent infrastructure standardization, not the end of it.
The next layer is the runtime around the protocol:
- the orchestrator that owns state transitions
- the policy engine that decides what is allowed
- the approval gate that turns consent into workflow state
- the store that persists artifacts and enables resume
- the trace system that explains what happened
- the memory architecture that separates immediate context from durable state
- the operator surfaces that make the whole thing inspectable
That is what the harness-engineering repo demonstrates in compact form today.
If you want a practical way to evaluate any new agent framework, protocol, or infrastructure startup, here is the question I would ask after they finish the MCP demo:
What happens next?
- Where is the workflow definition?
- Where is the approval boundary?
- Where is the policy decision recorded?
- Where is the persisted run state?
- Where are the traces?
- Where are the operator summaries?
- How do I resume a half-finished run?
- How do I inspect what the reviewer actually approved?
If the answer to those questions is fuzzy, then the system is still mostly interface theater.
If the answer is explicit, durable, and inspectable, then you are finally in the territory that matters.
That is the layer after MCP.