Artificial intelligence is entering a new engineering phase. For the last two years, the dominant conversation centered on prompt engineering: how to ask better questions, structure better instructions, and squeeze more reliable output from large language models. That work mattered, and still matters. But as models have become capable of planning, tool use, coding, browsing, testing, and acting over many steps, the practical bottleneck has shifted.
The central production problem is no longer simply how to prompt the model. It is how to build the runtime around the model so that the model can act effectively, safely, durably, and measurably.
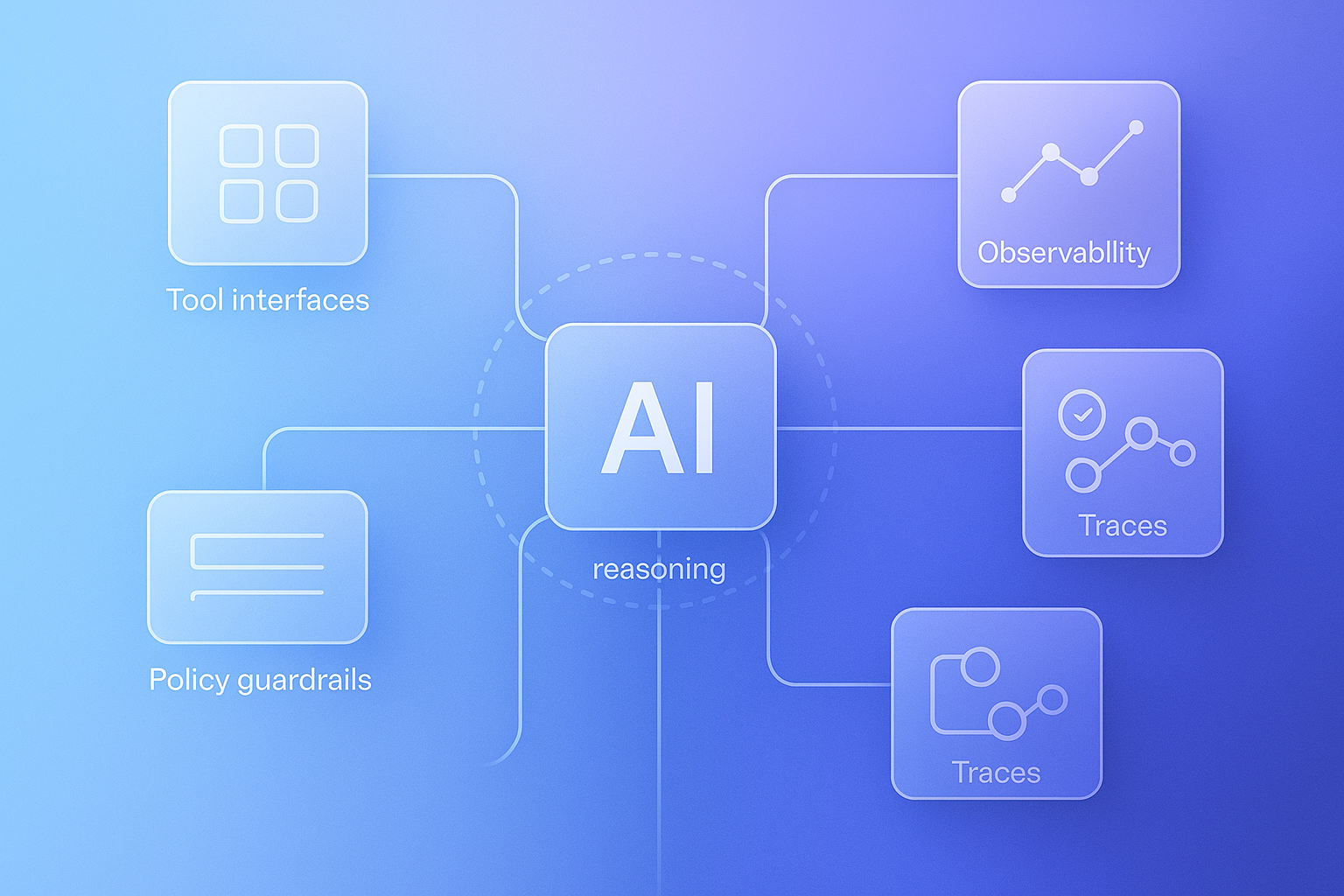
That runtime is the harness.
This white paper argues that harness engineering is becoming a foundational discipline for production AI systems. It sits at the intersection of platform engineering, developer tooling, workflow orchestration, safety engineering, eval design, and systems architecture. In an agentic system, the model is only one component. The harness determines what the model can see, what it can do, how it verifies progress, how it pauses, how it recovers, how it is evaluated, and how it remains governable under real-world constraints.
The core claim is simple:
In an agentic world, prompts influence behavior, but harnesses determine whether behavior is operationally usable.
That is the difference between an impressive demo and a system that can be trusted in production.
Executive Summary
Agentic harness engineering is the discipline of designing the environment, interfaces, controls, and feedback loops around an AI agent so it can do reliable work over time.
A production-grade harness typically includes:
- a clear task interface
- structured context and discoverable documentation
- typed tool contracts
- workflow orchestration and state management
- pause, approval, and resume mechanics
- artifact persistence and durable execution
- observability and tracing
- evaluation and regression detection
- policy, permissions, and isolation boundaries
- human oversight and escalation rules
Primary source material from OpenAI, Anthropic, OpenAI’s agent-evals guidance, the MCP specification, and Logic’s engineering analysis all converge on the same underlying lesson: agent quality is strongly shaped by the quality of the surrounding system.[1][2][3][4][5]
This white paper develops that thesis in detail, defines the field, distinguishes it from adjacent disciplines, lays out a reference architecture, proposes a maturity model, and offers an adoption roadmap for engineering teams.
1. Why This Topic Matters Now
OpenAI’s recent essay on harness engineering is valuable not because it introduces a catchy term, but because it makes visible a deeper shift already happening across the industry. In OpenAI’s account, the interesting claim is not merely that Codex generated large amounts of code. The more important claim is that the engineering team’s role moved upward: humans increasingly designed the conditions under which agents could ship reliably, rather than manually authoring each line of implementation.[1]
OpenAI describes an internal product built with effectively no manually written code, using Codex to generate not just application logic but tests, CI configuration, documentation, observability artifacts, and tooling. The consequence was a change in where engineering effort went. The hard problems became:
- making the repository legible to the agent
- structuring knowledge for progressive discovery
- exposing logs, metrics, traces, and UI state
- enforcing invariants with linters and tests
- enabling per-task isolation and validation
- shifting review and iteration into structured feedback loops
Anthropic’s guidance arrives at a complementary conclusion from a different angle. Their recommendation is to begin with simple, composable systems, invest deeply in tool quality and agent-computer interfaces, and only add more agentic complexity when it measurably improves outcomes.[2] OpenAI’s eval guidance pushes the same trend from the measurement side: once an agent system spans multiple turns, tools, and handoffs, output inspection is not enough. Teams need trace-level evaluation to know whether a workflow is actually improving or regressing.[3]
Meanwhile, the Model Context Protocol formalizes a standard way for hosts, clients, and servers to expose tools, prompts, and resources.[4] And Logic’s engineering essay frames the operational consequence in blunt terms: AI systems force teams to invest in practices they always knew were good engineering but often treated as optional, such as smaller files, stronger typing, faster tests, and stricter automation.[5]
Together, these sources point to the same reality. Models are no longer only generators. They are increasingly decision policies embedded in execution systems.
That means the surrounding system matters enormously.
2. Defining Agentic Harness Engineering
A precise definition helps separate enduring engineering concerns from temporary industry buzz.
Agentic harness engineering is the design of the runtime, interfaces, context architecture, control surfaces, and feedback loops that allow an AI agent to operate effectively and safely in the real world.
The harness includes, at minimum:
- the tool surface the agent may invoke
- the context architecture through which it learns about the system
- the workflow engine or runtime loop that governs execution
- persistence for state, artifacts, and traces
- approval, escalation, and cancellation boundaries
- observability and evaluation layers
- policy and permission enforcement
- environmental isolation and cleanup
This definition is intentionally broader than prompt engineering and narrower than the entire field of AI systems.
It is broader than prompt engineering because prompt wording is only one input into agent behavior.
It is narrower than “agent engineering” because not every part of agent engineering concerns the harness specifically. Model choice, fine-tuning, persona design, and product UX all matter, but harness engineering focuses on the execution substrate around action.
A useful mental model is:
- model = reasoning engine
- tools = actuators
- context = sensory input and working knowledge
- harness = operating system, control layer, and cockpit
- evals = quality and regression instrumentation
- human = supervisor for goals, taste, and exception handling
Under that framing, the harness is what turns latent capability into reliable operation.
3. Why Prompt Engineering Is No Longer Enough
Prompt engineering remains useful for single-turn tasks and still plays a role in agentic systems. But once models are allowed to call tools, write files, browse interfaces, update records, or act over long horizons, prompt quality becomes only one part of reliability.
A strong prompt cannot, by itself:
- make a hidden system observable
- create a durable approval gate
- provide resumability after a crash
- define the authority model for external actions
- guarantee tool input validity
- enforce architecture boundaries
- distinguish a good final output from a bad workflow trace
This is why many agent demos fail when moved into production. The model itself may be capable. The environment around it is not.
Typical failure modes in weak harnesses include:
- vague tool descriptions causing wrong-tool selection
- missing or stale documentation leading to bad assumptions
- no structured state, so a run cannot pause or resume cleanly
- side effects executed without explicit approval or policy checks
- no fast verification loop, so the agent believes it succeeded without proof
- slow or flaky environments that destroy autonomy economics
- no trace or audit layer, making failures impossible to diagnose
In other words: the model is often not the first thing that breaks.
4. The Fundamental Shift: From Generation to Control Systems
The deepest conceptual change is that AI systems are becoming closer to control systems than static generators.
In a classical control loop, a system:
- observes state
- decides on an action
- acts through actuators
- observes resulting state again
- corrects based on feedback
Agentic AI systems now increasingly work the same way. The model reasons over context, selects tools, acts, receives environmental feedback, and iterates until a stopping condition, success criterion, or escalation trigger is reached.
This is exactly why Anthropic emphasizes ground truth from the environment during execution.[2] And it is why OpenAI’s trace-grading guidance focuses on workflow-level evaluation rather than only final answers.[3]
The practical implication is important: once an agent can act, you should think less like a copywriter and more like a systems engineer.
The questions become:
- What state can the agent actually observe?
- How constrained are its available actions?
- What feedback does it receive after action?
- How does it detect completion versus drift?
- What happens when it gets stuck?
- When must it pause for human review?
- How do you know whether it improved after a change?
These are harness questions.
5. Core Components of a Production Agent Harness
A useful harness can be described as a layered architecture. Different teams will implement these layers differently, but the functions themselves recur consistently.
5.1 Task Interface
The task interface is how humans specify intent.
Typical inputs include:
- tickets
- bug reports
- PRDs
- change requests
- incident records
- support conversations
- research briefs
- approval requests
A good task interface does more than capture prose. It also captures verifiable success criteria. Agents work better when the target condition is legible, measurable, and connected to the environment.
Poor task definition produces ambiguous autonomy. Good task definition reduces wasted search.
5.2 Context Architecture
Context architecture determines what the agent can discover.
OpenAI’s account strongly argues against the giant monolithic instruction file. Their practical lesson is to “give the agent a map, not a manual.”[1] That is one of the most important design principles in modern harness engineering.
A healthy context architecture usually includes:
- a concise top-level guide
- indexed design docs
- architecture maps
- plan files
- API schemas
- decision logs
- active and completed execution plans
- known constraints and quality rules
The goal is progressive disclosure: the agent starts from a stable, compact entry point and follows links into deeper source-of-truth artifacts as needed.
Too little context makes the agent blind. Too much context makes it lost.
5.3 Tool Surface and Agent-Computer Interface
Anthropic explicitly frames tool design as an agent-computer interface problem, analogous to human-computer interface design.[2] This is a powerful framing.
Tools are not just functions. They are the practical action vocabulary of the agent.
A high-quality tool surface should be:
- clearly named
- narrowly scoped
- schema-rich
- easy to distinguish from adjacent tools
- explicit about side effects
- documented with examples and edge cases
- hard to misuse by accident
The MCP specification formalizes an interoperable way to expose tools, prompts, and resources, but its own security section makes clear that tools are powerful and potentially dangerous, and that explicit user authorization remains essential.[4]
This is an important point: standardization helps interoperability, but it does not remove the need for harness-level policy, consent, and control.
5.4 Workflow Orchestration and State
A reliable agent system needs explicit workflow state.
That includes at least:
- run identity
- current step
- pending action
- approval requirement
- retry count
- produced artifacts
- completion status
- failure status
- stopping conditions
Without explicit state, “human in the loop” often degrades into vague chat etiquette. With explicit state, approval becomes a real workflow primitive.
OpenAI’s experience also highlights the importance of execution plans and versioned decision history.[1] In practical systems, plans should be first-class artifacts, not invisible thought bubbles.
5.5 Durable Execution and Persistence
Durability is where many demos stop and real systems begin.
Durable execution means a run can survive:
- process restarts
- temporary dependency failures
- human approval delays
- long-running work intervals
- deferred follow-up steps
Persistence should cover:
- run state
- intermediate artifacts
- event traces
- logs of decisions and tool invocations
- final outputs
If the only copy of “what happened” lives in transient memory or chat history, the system is fragile by default.
5.6 Verification Layer
Coding agents are a favorable domain precisely because code is verifiable through tests, lints, and execution results. Anthropic calls this out directly, and Logic argues that AI magnifies the value of fast, exhaustive checking.[2][5]
The verification layer may include:
- unit and integration tests
- end-to-end tests
- linters and formatters
- schema validation
- type checks
- static analysis
- boundary validation
- architecture rules
- performance thresholds
- content review checks
The central principle is that correctness should come from environment feedback, not agent confidence.
5.7 Observability and Tracing
OpenAI’s case study is especially strong on observability. They made logs, metrics, traces, and UI state directly available to Codex, often inside isolated per-task environments.[1]
That is not a nice-to-have. It is how the agent stops guessing.
A mature harness should expose at least:
- structured logs
- timing and latency metrics
- step-level traces
- error reasons
- screenshots or DOM state where UI work matters
- resource usage and performance signals
Modern agent traces play a role analogous to application logs, but richer. They show not just what failed, but how the workflow navigated, which tools were called, where retries occurred, and when escalation happened.
5.8 Evaluation and Regression Detection
OpenAI’s eval guidance argues that trace grading is the fastest path to discovering workflow-level problems.[3]
This is critical. Final outputs alone are often misleading. A result may look correct while the process behind it is unsafe, expensive, wasteful, or fragile.
Important evaluation questions include:
- Did the agent choose the right tool?
- Did a handoff happen when it should have?
- Did it violate a policy?
- Did a routing or prompt change improve the full workflow?
- Did retry behavior remain within budget?
- Did it escalate at the right moment?
This turns harness engineering into a measurable optimization discipline rather than a collection of anecdotes.
5.9 Governance, Permissions, and Human Oversight
The harness must encode what the agent may do autonomously and what it may not.
This includes:
- action classes by risk level
- approval gates
- rollback behavior
- retry budgets
- stop conditions
- kill switches
- escalation paths
- permission scoping
- audit records
The MCP specification’s security guidance is unambiguous: users must explicitly consent to and understand operations, retain control over data sharing and actions, and receive clear authorization surfaces for tool use.[4]
This is one reason the industry should resist the fantasy that agents become trustworthy merely by becoming more intelligent. Intelligence without control surfaces is not reliability.
5.10 Isolation and Safe Execution
OpenAI and Logic both stress isolated task execution, whether through worktrees, per-task runtime environments, or other sandboxing approaches.[1][5]
Isolation matters because agents amplify the cost of hidden coupling.
A serious harness should think about:
- per-task environments
- unique ports and databases where needed
- scoped credentials
- disposable artifacts
- sandboxed file boundaries
- cleanup and garbage collection
- protection from cross-run contamination
Without isolation, multi-agent or multi-run systems become difficult to reproduce, debug, and trust.
6. Harness Engineering Versus Adjacent Disciplines
Clarity improves adoption. Harness engineering is related to, but distinct from, several nearby fields.
Prompt Engineering
Focuses on how inputs are phrased for the model.
Agent Engineering
Covers the broader design of agent behavior, memory, orchestration, and product integration.
Platform Engineering
Builds internal infrastructure and paved roads for human developers.
Eval Engineering
Designs measurement, test sets, graders, and regression workflows.
Safety Engineering
Constrains harmful behavior, policy violations, and unsafe outputs or actions.
Harness engineering overlaps all of these, but its center of gravity is the operational runtime around action.
It is where these concerns meet.
7. Design Principles That Appear Robust Across Sources
Despite differences in emphasis, the source set converges on several robust principles.
7.1 Simplicity Before Architecture Theater
Anthropic’s advice is especially clear here: begin with simple systems, and add complexity only when it demonstrably helps.[2]
This matters because the current market overproduces orchestration complexity. Many teams jump too quickly to multi-agent graphs, handoff networks, or elaborate frameworks before they have mastered basic loops, tools, and evals.
7.2 Legibility Is a First-Class Requirement
OpenAI’s article repeatedly emphasizes repository legibility.[1]
If the agent cannot discover something, it effectively does not exist. Knowledge stranded in Slack, Google Docs, or human memory is operationally invisible.
7.3 Turn Taste Into Mechanism
OpenAI describes encoding “golden principles” into linters, checks, and recurring cleanup processes.[1] Logic makes a similar point from an engineering-practice perspective.[5]
The broader principle is: do not rely on the model to remember your preferences. Encode them into the environment.
7.4 Fast Feedback Compounds
Fast verification loops are leverage. Slow feedback destroys autonomy economics.
If an agent waits 20 minutes for each correctness signal, iteration becomes expensive and humans inevitably reclaim the loop. Logic’s emphasis on minute-scale comprehensive testing reflects this exactly.[5]
7.5 Ground Truth Must Come From the Environment
Anthropic’s guidance on environmental feedback is essential.[2]
The model should not only infer whether it succeeded. It should observe whether it succeeded.
7.6 Trace Quality Matters as Much as Output Quality
OpenAI’s eval guidance makes this explicit.[3]
Production systems should evaluate not only whether the answer looked right, but whether the workflow remained aligned, safe, and efficient.
8. Common Failure Modes in Weak Harnesses
Most teams will not fail because they picked the wrong model first. They will fail because the harness has hidden weaknesses.
Common failure modes include:
8.1 The Giant Prompt Anti-Pattern
A single huge instruction file becomes stale, unverifiable, and context-hungry.
8.2 Tool Overload
Too many vague tools with overlapping semantics increase error rates and make debugging harder.
8.3 Hidden Institutional Knowledge
Critical design decisions live outside the environment the agent can inspect.
8.4 Weak Verification
No fast, trusted feedback loop exists, so the agent confuses “plausible” with “correct.”
8.5 Slow Runtime Environments
Expensive loops make autonomy uneconomical.
8.6 Poor Isolation
Runs interfere with one another through shared state, ports, caches, or credentials.
8.7 No Trace-Level Evals
Teams inspect a handful of outputs and miss systemic workflow regressions.
8.8 Over-Autonomy Before Control Maturity
Organizations grant write, merge, or operational authority before approval, rollback, and policy systems are strong enough.
9. A Practical Maturity Model for Agentic Harness Engineering
A useful organizational framework is a five-level maturity model.
Level 1 — Assisted Generation
- model produces suggestions or drafts
- humans execute actions manually
- little or no structured tool use
- minimal evals or traces
Level 2 — Tool-Using Agent Workflows
- agents call tools through structured interfaces
- runs may span multiple steps
- basic logs exist
- humans remain deeply involved
Level 3 — Controlled Agent Runtime
- explicit workflow state
- pause, approval, and resume support
- persistent artifacts and traces
- test and lint loops integrated
- risk classes and permissions begin to harden
Level 4 — Measured and Governed Harness
- trace grading and repeatable eval datasets
- strong observability
- reliable isolation boundaries
- policy enforcement is mechanical, not social
- cost, latency, and retry budgets are visible
Level 5 — Scaled Agentic Platform
- multiple specialized agents or workflows with clear contracts
- strong handoff semantics
- durable execution across longer horizons
- mature governance, rollback, and auditing
- organizational knowledge is machine-legible and continuously maintained
Most teams should aim to climb this ladder gradually. Jumping directly from Level 1 to Level 5 usually creates architecture theater and fragile autonomy.
10. Strategic Implications for Engineering Organizations
The rise of harness engineering may reshape how engineering labor is allocated.
Historically, senior engineers spent large amounts of effort directly implementing product logic. In an agentic setting, more leverage shifts toward:
- designing execution environments
- defining interfaces and invariants
- building fast validation loops
- structuring knowledge for discoverability
- measuring workflow behavior over time
- encoding organizational judgment into automation
That does not make human expertise less important. It changes where expertise compounds.
One way to state the shift is:
- junior work used to be typing the code
- senior work used to be reviewing and architecting it
- agentic senior work increasingly includes encoding judgment into the harness so machines can execute within it
This looks a lot like a fusion of platform engineering, DX, safety, and workflow design.
11. Adoption Roadmap for Teams
For teams taking this seriously, a staged adoption path works best.
Phase 1 — Make the Environment Legible
- create a concise top-level map
- organize architecture and design docs
- define task and acceptance-criteria templates
- make source-of-truth artifacts discoverable
Phase 2 — Make Correctness Cheap
- speed up lint, type, and test loops
- reduce flakiness
- enforce a few high-value invariants mechanically
- shrink files and improve naming
Phase 3 — Make Runtime State Explicit
- introduce run identity and workflow state
- support pause, approval, and resume
- persist artifacts and traces
Phase 4 — Make Behavior Observable
- expose logs, metrics, traces, and tool outcomes
- add dashboards or trace views
- surface failure reasons clearly
Phase 5 — Make Improvement Measurable
- add trace graders
- create eval datasets
- benchmark prompt, tool, and routing changes
- track latency, cost, retry, and escalation metrics
Phase 6 — Expand Autonomy Gradually
- start with draft generation
- then allow tool use in trusted sandboxes
- then support PR creation or structured updates
- leave merge, deploy, or high-risk operational power for last, if at all
12. Open Questions
The field is early, and several questions remain unresolved.
- How well does architectural coherence hold over years in fully agent-generated systems?
- What is the right balance between human aesthetic judgment and machine-optimized regularity?
- How should organizations measure long-horizon agent quality beyond task completion?
- When do multi-agent review loops catch errors, and when do they merely reinforce shared blind spots?
- What is the economically optimal level of autonomy, rather than the technically maximal one?
- How portable are current harness practices across domains where correctness is subjective or feedback is delayed?
These are not minor questions. They will likely define the next wave of serious research and tooling.
13. Conclusion
Harness engineering is not a marketing embellishment for prompt engineering. It is a shift in where engineering value lives once AI systems start acting in the world.
The most important lesson from the current wave of agent practice is not that models can write code, browse the web, or call tools. It is that once they can do those things, software quality depends increasingly on the control system around them.
That means:
- prompts still matter, but are insufficient
- tool interfaces matter more than most teams expect
- documentation must become machine-legible
- state, approvals, and resumability are architectural concerns
- traces are the raw material of improvement
- evals must grade workflows, not only outputs
- human judgment must be compiled into guardrails, policies, and verification layers
Or more bluntly:
Prompt engineering gets the demo. Harness engineering gets the system.
The teams that internalize this shift earliest will not merely have better AI features. They will have more governable, testable, and scalable operating models for building software with agents.
That is why agentic harness engineering deserves to be treated as a real engineering discipline.
References
- OpenAI, “Harness engineering: leveraging Codex in an agent-first world.” https://openai.com/index/harness-engineering/
- Anthropic, “Building effective agents.” https://www.anthropic.com/engineering/building-effective-agents
- OpenAI API Docs, “Evaluate agent workflows.” https://developers.openai.com/api/docs/guides/agent-evals
- Model Context Protocol Specification (2025-06-18). https://modelcontextprotocol.io/specification/2025-06-18
- Steve Krenzel, Logic, “AI Is Forcing Us To Write Good Code.” https://bits.logic.inc/p/ai-is-forcing-us-to-write-good-code
- OpenAI, “Building agents.” https://developers.openai.com/tracks/building-agents